






What are Liquid LLMs and why are top companies betting on AI that learns while you sleep? Learn how adaptive, continually-learning models could reshape recommendation engines, chatbots, and data pipelines overnight.
Liquid LLMs are still a hypothesis, not a product you can license today. Drawing on recent breakthroughs in liquid neural networks from MIT CSAIL, this article argues that Large Language Models (LLMs) will soon adapt continuously to live data learning at night so they can compete the next day. We weave the latest academic results with market signals to show why CIOs and Chief Product Officers should begin low‑risk pilots now. A four‑step playbook closes the loop.
Unlike conventional AI models that rely on the transformer architecture, Liquid LLMs are powered by liquid neural networks. Inspired by how biological neurons work, these networks use mathematical equations to capture neuron behavior dynamically over time. This design allows the model to adapt in real time, remain more interpretable and transparent, and achieve complex outcomes with fewer neurons compared to traditional systems.
“I believe tomorrow’s most valuable firms will run models that learn every day, because public research shows measurable accuracy decay inside a single quarter.”
Tech leaders should explore “liquid‑style” techniques now so they are ready when tool chains mature.
Problems We Saw While Working With LLMs
Last quarter three recommendation stacks I reviewed missed surging demand because their models were six days old. Each analytics team scrambled to hot‑fix, but the spike was finished before new weights deployed. Revenue left first, brand trust followed.
Why does this keep happening?
- Flash promotions reshape click‑through rates between sunrise and sunset.
- Social slang mutates sentiment faster than weekly language updates.
- Fraud rings probe algorithms in real time.
A joint study by Harvard, MIT, and Monterrey Tech found that 91% of production ML systems drift within 12 months. Staleness is the new technical debt.
Why We Call Them Liquid LLMs and What the Name Signifies?
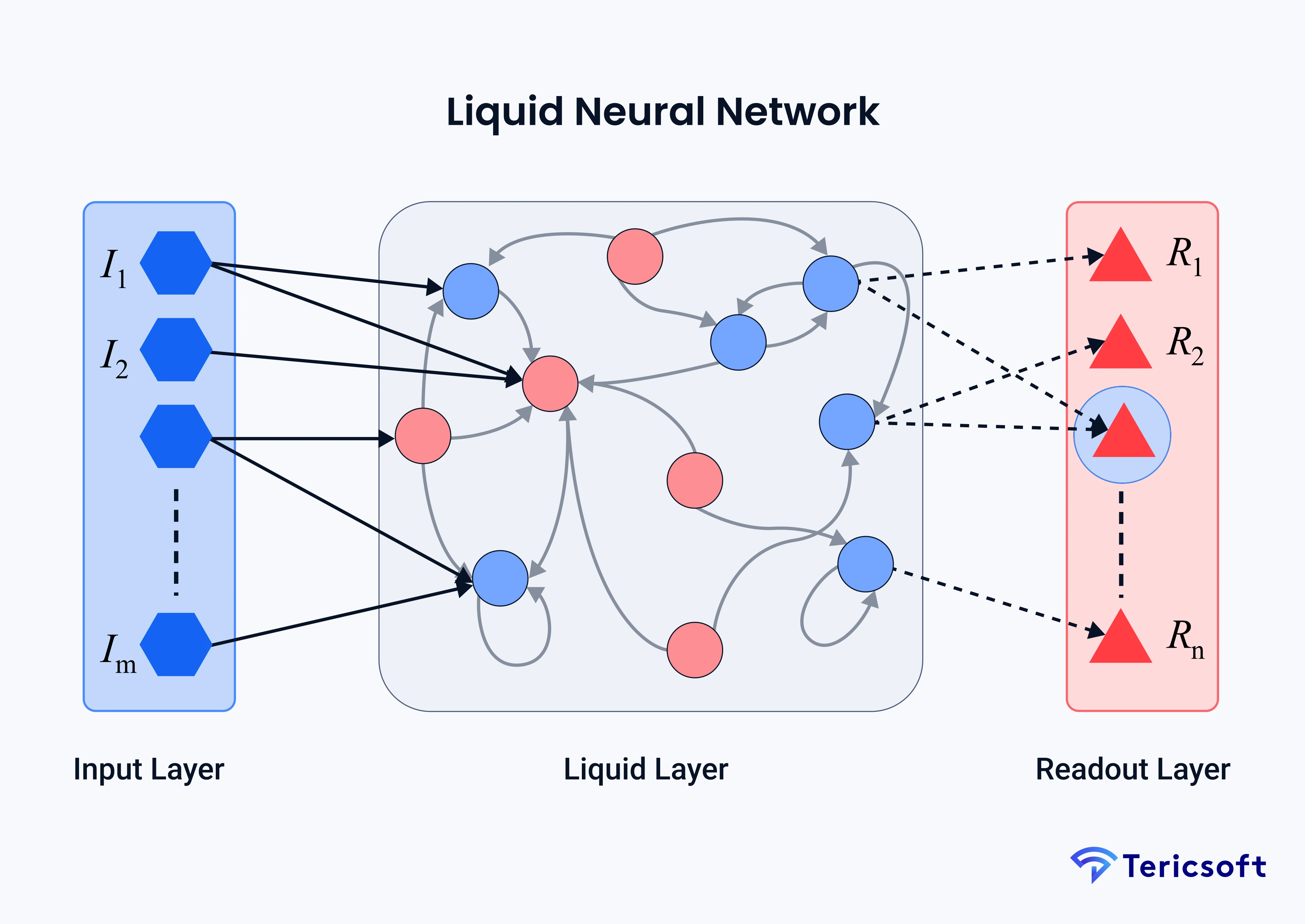
Liquid neural networks come from work led by Ramin Hasani at MIT CSAIL. Their liquid time‑constant architecture lets each neuron follow a differential equation that updates continuously with incoming signals, much like a spring that compresses and rebounds. Research indicates Liquid Neural Networks can achieve LSTM‑level performance with far fewer parameters and dramatically lower power use, e.g. using ~19 neurons to match models with over 100,000, cutting energy and memory needs by an order of magnitude.
Setting the stage:
Before we bring these ideas to language, remember the shared goal: keep intelligence fresh without burning the data‑science budget. Two prototype directions matter.
- Continual learning LLMs keep models from drifting by accepting small, frequent updates.
- Adaptive language models refine attention heads in the middle of a conversation so they can track the user’s evolving context.
Continual learning LLM:
Imagine a transformer that accepts a micro‑batch of fresh data at three in the morning, adjusts only the weights touched by drift, and returns to service before breakfast. No vendor currently ships this capability, but DeepMind’s Gemini roadmap explores advanced dynamic controller research, including large-context reasoning, sparse Mixture‑of‑Experts, and adaptive ‘thinking’ mechanisms. The purpose is simple: slow or reverse accuracy decay without the carbon cost of a full retrain.
Adaptive language models:
Traditional fine tunes freeze most of the transformer, retrain days later, and redeploy. A liquid formulation could let individual attention heads nudge their hidden state on the fly. Dynamic does not mean chaotic; the spring settles once it absorbs the new pattern. The benefit would be chat experiences that remain consistent even as slang or policy changes mid‑conversation.
Blockers most teams face:
- Noisy labels. Continuous learning amplifies bad data unless curation improves.
- GPU scheduling. Clusters optimized for giant weekly jobs struggle to deliver minute‑scale batches.
- Audit checklists. Most frameworks assume static weights and quarterly fairness tests.
Difference Between Transformer based vs Non‑Transformer based LLMs
The modern transformer LLM, exemplified by GPT‑4 and Gemini, uses multi‑head self‑attention to map every token to every other token in a context window. Strengths include massive parallelism, long context lengths, and a rich ecosystem of tooling. Weaknesses are parameter bloat, costly retrain cycles, and drift between updates.
A non‑transformer LLM in the liquid style replaces rigid attention layers with liquid cells whose internal state evolves through time‑continuous equations.
Example: the 2023 Liquid‑GPT prototype from Northeastern University used only 36 million parameters to reach 84 percent of base GPT‑2 quality on WikiText while training four times faster on low‑power hardware.
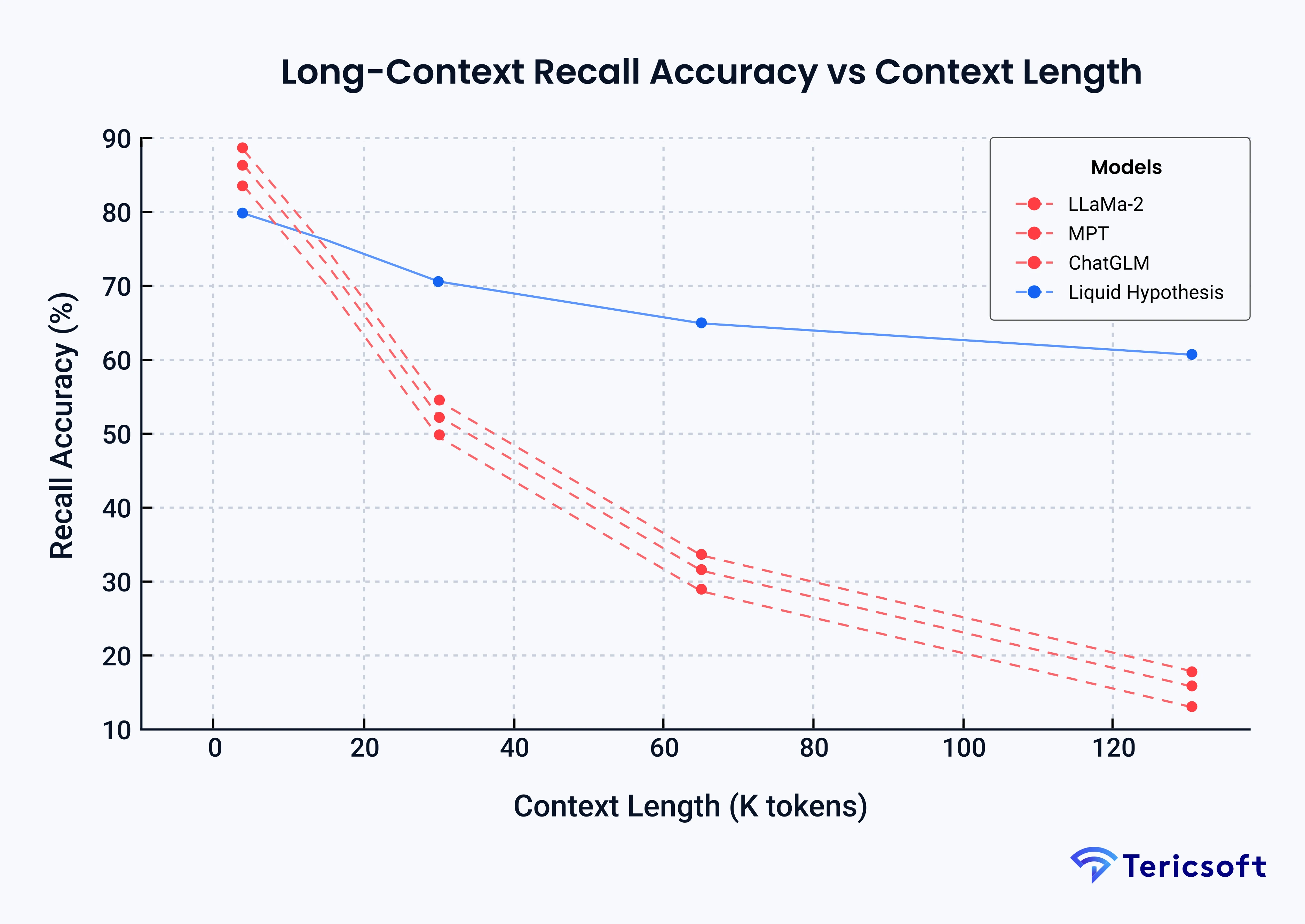
Current drawback: Liquid LLMs still struggle with long‑range dependencies because liquid cells integrate information locally over time. Researchers have not yet demonstrated context windows beyond two thousand tokens, and gradient stability remains an open question for very deep stacks. A non‑transformer LLM in the liquid style replaces rigid attention layers with liquid cells whose internal state evolves through time‑continuous equations.
Contracts, Pipelines, and Guardrails for Liquid Learning
Today’s AI licensing still revolves around tokens counted and GPU hours burned. If models start improving themselves while we sleep, value will migrate to fresh business outcomes delivered before breakfast. The next sections unpack how contract terms, real‑time data plumbing, and safety guardrails must evolve together to support that leap.
Learning as a Service
According to IDC forecasts, a majority of enterprises are expected to shift toward outcome-based AI purchasing models by the late 2020s. Imagine an invoice that reads plus 1.8 percent average basket size instead of twelve million tokens. Continuous learning would align technical delivery with this commercial logic.
Dynamic Language Model: A Pipeline Blueprint
A conceptual framework for continuously adapting AI systems through real-time data flow, incremental learning, and market-aware optimization.
- Data aqueducts stream only high‑signal events.
- Incremental training chips such as Mythic M2000 process micro‑batches during low‑tariff hours.
- Elastic optimizers merge small gradient steps before markets open.
Model governance framework
Regulation (EU) 2024/1689 (Al Act) mandates continuous post-market monitoring of high-risk Al systems beginning 2 August 2026 (Article 72), with risk management required throughout the system life cycle (Article 9). Cost overhead is less than five percent because checks run beside micro‑batch jobs.
Four‑Week Pilot Roadmap
Below is a four‑week roadmap that any data leader can adapt for implementation of Liquid LLMs in the near future.
Week 1 - Assess
- Map data streams that shift daily.
- Measure event to prediction latency.
- Ensure full model lineage.
Week 2 - Pilot
- Select one KPI, for example search relevance.
- Feed nightly micro‑batches on ten percent of traffic.
- Success means arresting drift or gaining 0.3 percent after fourteen nights.
Week 3 - Scale
- Reserve fifteen percent GPU headroom.
- Automate model cards in CI.
- Assign a data curator.
Week 4 - Govern
- Fail CI if latency exceeds two hundred millisecond P95.
- Hash every weight delta.
- Run fairness metrics alongside accuracy.
Lessons Learned From Early Experiments
Success pattern: A fashion marketplace prototype reduced return rates by fourteen percent after nightly size advice corrections. Pipeline ran on one idle A100 during off‑peak hours. Results were internal, methodology will appear in a forthcoming benchmark.
Cautionary tale: A fintech chatbot generated sarcastic replies because toxicity filters lagged behind core model micro‑updates.
Lesson: Governance must move as fast as learning.
Signals Lighting the Road Ahead
- Edge liquid phones: Qualcomm AI Engine v3 advertises always‑on learning drawing less than one milliamp. This suggests sub‑1 watt micro‑gradient updates are feasible on device.
- Quantum‑primed dreaming: IBM Eagle processor exceeds 150,000 circuit layer operations per second, accelerating transformer sampling. Internal demos hint at a twelve percent improvement, but the figure is unpublished.
- Midnight board meetings: Scenario planning agents could digest KPIs at two in the morning and deliver options by six thirty. This remains speculative yet every technical prerequisite already exists.
Future Vision: Overnight Self‑Improvement in the 24‑Hour Economy
Adaptive pricing loops: By 2028 many consumer platforms will refresh recommender weights every sixty minutes to ride regional demand waves. One Latin American marketplace disclosed in a private engineering forum that experimental hourly embedding retrains lifted gross merchandise value by roughly one percent during flash‑sale events (anonymised anecdote, May 2025)
Just‑in‑time knowledge workers: Legal and policy bots could ingest the last twelve hours of regulatory releases and draft contract clauses before markets open.
These scenarios remain directional, yet the primitives are already visible in edge chips, streaming feature stores, and continuous evaluation pipelines.
Closing Thought: Your Models Will Work the Night Shift
Liquid techniques for non‑transformer LLMs are not ready for full production, but the ingredients are converging. Executives who practice continual learning today will sprint when mature frameworks land. The rest will wake to find that their competitors literally learned while they slept.

A Liquid LLM is a non‑transformer foundation model using structured adaptive operators for efficient sequential data learning.
It uses dynamical‑systems inspired units instead of attention, improving memory and inference efficiency.
They excel at long‑context reasoning, multilingual understanding, math, language tasks, and edge deployment.
Yes, Liquid offers on‑prem customization and licensing, letting organizations fine‑tune privately within firewalls.
They deliver faster inference, lower compute needs, longer context handling, and better adaptability than transformers.


