Can large language models truly understand what you mean, or are they just predicting patterns? Learn how Context Engineering is redefining Al memory, reasoning and reliability, and why context, not size, is becoming the real measure of machine intelligence.
In the era of large language models, many teams still treat Al like a magic black box: you write a prompt, feed it to the model, get an answer, repeat. That is prompt engineering. But what happens when your Al assistant forgets what you said five minutes ago? Or produces brilliant answers in one session and then becomes bewildered in the next? The missing piece is Context Engineering, the discipline of designing systems so your LLM understands, not just responds.
At Tericsoft we believe the frontier of intelligence lies not in bigger models but in smarter context: how you write, select, compress and manage what the model knows. In this blog we'll walk you through what context engineering is, how it differs from prompt engineering, why LLMs struggle without it, the core strategies and building blocks, how to avoid failure modes, how to apply it to agentic systems, the business impact, and how Tericsoft builds context-aware LLM solutions for startups and enterprises alike.
When Machines Forget: The Real Limitation of LLMs
Imagine you build a chatbot that answers your customer's questions perfectly in one session, but the next time the user chats it asks again for their name and forgets that you'd already captured it. That happens because the model lacks memory and continuity. The illusion of "understanding" in today's LLMs often hides its true fragility: the model doesn't remember unless you build memory.
You may have heard the analogy: LLMs are like extremely fast CPUs. But what about their RAM? That is the context window. Without sufficient working memory or the right context, the model struggles to maintain logic, recall earlier steps and produce coherent multi-step workflows. The true frontier of LLM intelligence isn't simply more parameters, it is context, not just the surface prompt.
"There's a great phrase, written in the '70s: 'The definition of today's Al is a machine that in make a perfect chess move while the room is on fire.'It really speaks to the limitations of Al... if we want to make more helpful and useful machines, we've got to bring back the contextual understanding."
— Fei-Fei Li, Co-Director of the Stanford Institute for Human-Centered Artificial Intelligence.
According to leading research, one of the main causes of failure in agentic Al systems is ambiguity, mis-coordination and unpredictable system dynamics rather than simple prompt errors.
Here's a striking insight: in long-context QA tasks, even the most advanced models still "fail due to context grounding issues" in roughly 17 percent of test cases.
What Is Context Engineering?
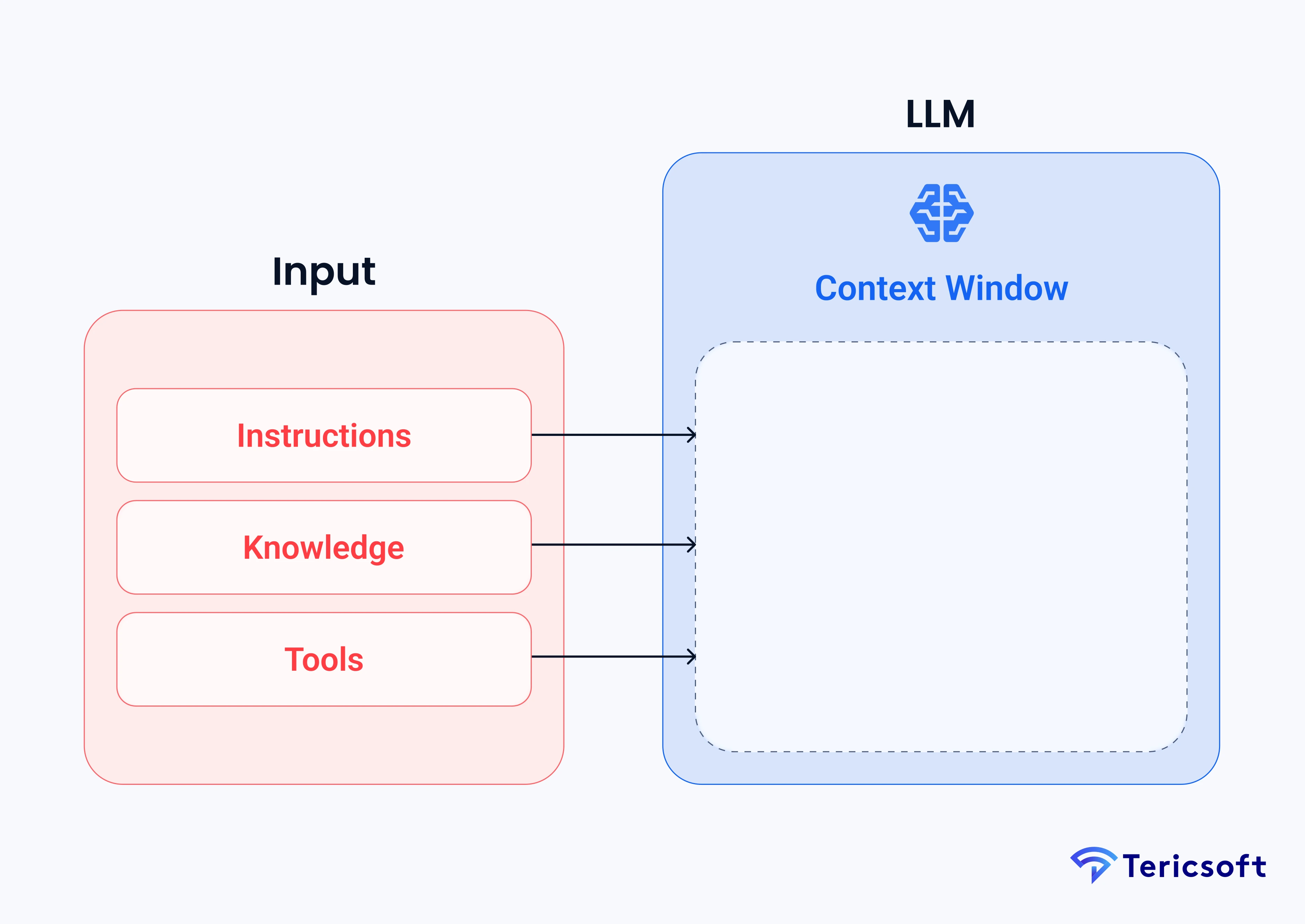
Context Engineering is the discipline of designing and building dynamic systems that supply the right background information, tools, memory and workflow so that an LLM can carry out tasks meaningfully, not just respond to a prompt. It is the art and science of filling the context window with just the right information at each step of an agent's trajectory.
Think of it this way: if the LLM is a CPU, then the context window is its RAM. Just as an operating system must decide what to load into RAM to ensure efficient execution, context engineering decides what information goes into the model's working memory to ensure it remains effective.
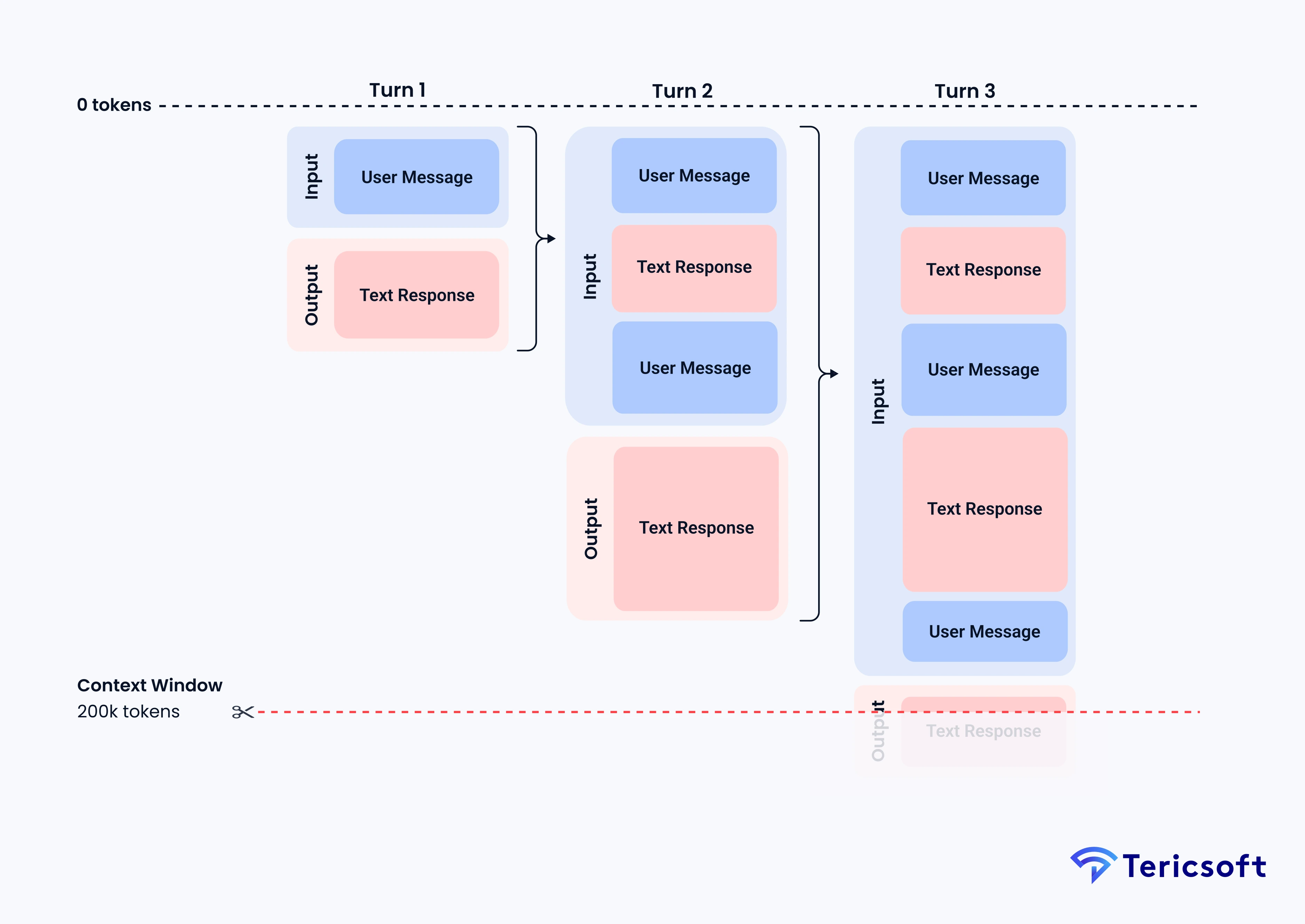
Real scenario: An Al agent loses its workflow mid-process because its context window overflows. Suppose you've built a research-assistant tool using an LLM. The user gives it five PDFs, the agent opens each, takes notes, generates a summary, then proceeds to recommend actions. Mid-way the model asks the user for the same document again or provides inconsistent advice. Why? Because earlier parts of the conversation or retrievals got trimmed out of the context window. That is a context engineering failure.
In short, the model may have the intelligence, but unless you properly manage its context, it cannot maintain continuity and truly function as an assistant.
Why LLMs Struggle Without Context - The Core Problem
At the heart of context loss lies a simple but critical constraint: the limited amount of information an LLM can hold at once.
The token-limit dilemma: short-term memory, long-term amnesia
One of the key limitations of LLMs is the context window, the maximum number of tokens the model can "see" at once. When you exceed this limit, older messages or retrieved documents may be truncated or ignored. The result: what practitioners call long-term amnesia in your chatbots or agents.
The pain of repetitive user instructions ("I just told you that!")
Ever asked an LLM to continue a conversation and it asks you for information you already shared? That happens because the model no longer has the context of earlier messages, or worse, the prompt you gave got buried beneath noise, irrelevant retrievals or stale memory fragments.
Real scenario: Customer support LLM misinterprets user tone after 10 messages
Imagine you deploy a customer-support assistant that handles many turns. On message 11 it misreads a frustrated user as cheerful because the tone signal from messages 1-10 has been lost or drowned out by irrelevant context. That failure costs the business tokens (more API calls), user trust and productivity.
Here's another insight: according to industry research, organizations report that roughly 30 percent of Al projects stall because the system lacks the proper memory and context retrieval infrastructure.
Source: Gartner
Context Engineering vs Prompt Engineering vs Intent Engineering
While prompt engineering, context engineering and intent engineering all improve how LLM systems perform, they operate at different layers. Prompt engineering improves instructions, context engineering improves what the model knows, and intent engineering improves what the system is trying to achieve.
Prompt Engineering: The surface-level fix
Prompt Engineering focuses on crafting the best single instruction or few-shot examples you give to an LLM at one time. It is about phrasing, formatting, defining role, examples and constraints. For many generation tasks, that is sufficient.
Context Engineering: The long-term solution
Context Engineering addresses the infrastructure around the LLM: how you maintain history, retrieval, memory, tool usage, token budgets, context windows and dynamic workflows.
Intent Engineering: The decision-alignment layer
Intent Engineering defines the goal, priority and success criteria behind the workflow. It ensures the AI stays aligned with the user’s real objective across multiple steps, not just the current task.
"The frontier is no longer in prompting. It's in understanding context at scale."
— Sam Altman, CEO of OpenAI
Real scenario: Sales AI great with a prompt, fails after 10 steps
A sales assistant built with prompt engineering may perform well when asked: “Create a sales email for this product.” But when asked: “Now consider the customer responded with this objection, craft a rebuttal and update the price accordingly,” the system may fail.
If memory, retrieval and state are missing, it becomes a context engineering problem. If the AI optimises for the wrong outcome, such as speed instead of conversion, it becomes an intent engineering problem. Together, these layers turn outputs into reliable outcomes.
Comparison chart: Prompts vs Context graphs vs Memory systems

The Context Model - How LLMs Store and Retrieve Meaning
Behind every context-aware system lies an invisible architecture. It decides what information the model keeps, what it forgets, and how it retrieves the right data at the right moment.
The hidden architecture of context: embeddings, relevance ranking, token prioritization
Under the hood, context engineering involves more than just passing text. It often requires embeddings (vector representations of knowledge or memory), relevance ranking (which retrievals to include), token prioritization (what stays in the window) and memory management (what to persist for later). For example, a RAG (Retrieval-Augmented Generation) pipeline might index documents, embed queries, fetch top-k and send fragments to the LLM alongside your prompt.
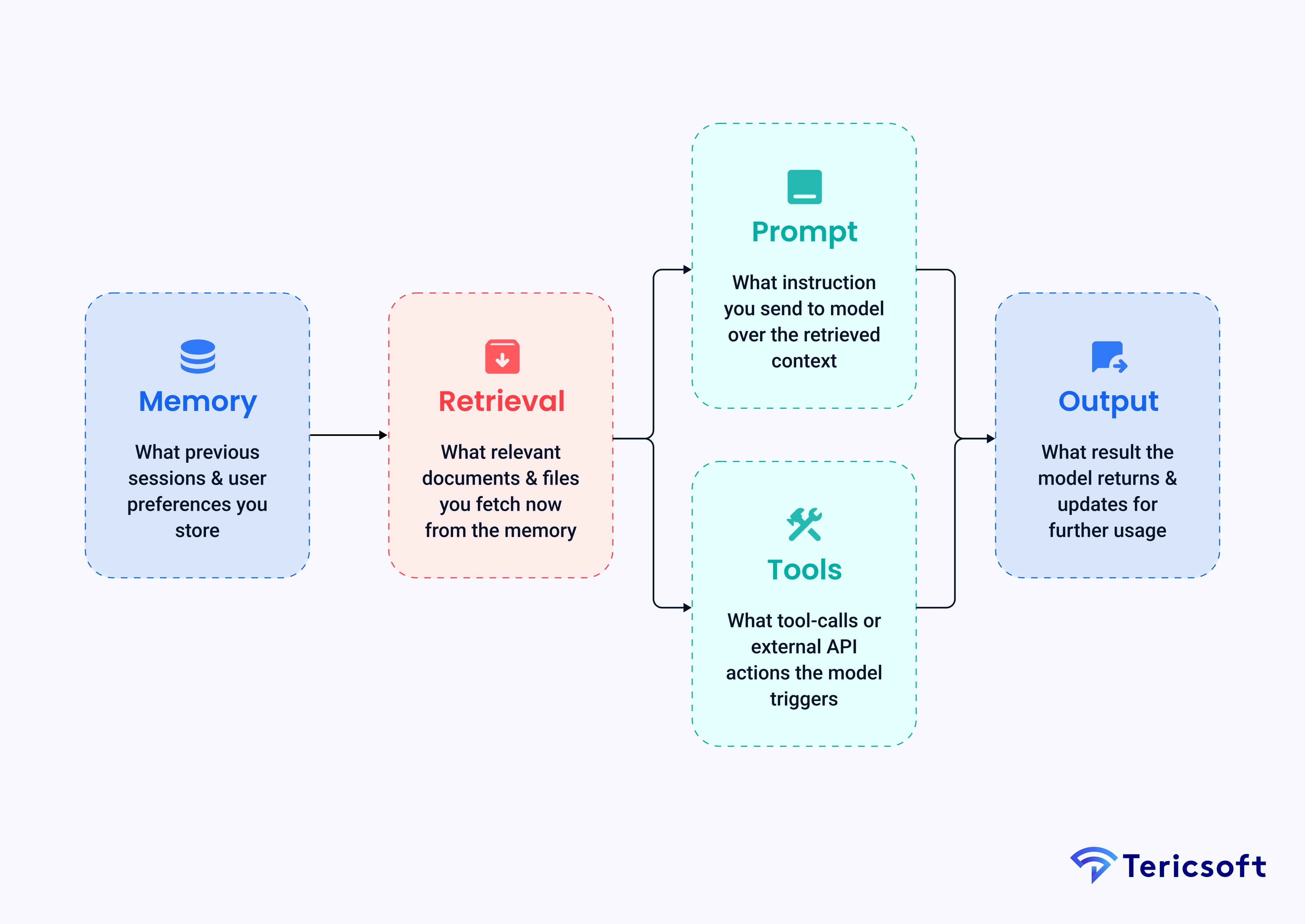
Imagine your system has layers:
- Memory: what past sessions or user preferences you store
- Retrieval: what relevant documents you fetch now
- Prompt: what instruction you send the model with retrieved context
- Tool usage or Action: what tool-calls or external API actions the model triggers
- Output or Update: what result the model returns, and what memory you update for next time
Real scenario: Your LLM pulls wrong data from internal docs. Let's say you have a product-FAQ dataset. The retrieval engine fetches an outdated FAQ because your relevance ranking wasn't updated. The model happily uses it and gives flawed advice. That is a breakdown in your context model.
Another insight: recent benchmarks found that even state-of-the-art long-context models hallucinate with a frequency nearing 41 percent in domain-specific ultra-long contexts.
Souce: Arxiv
The Four Core Strategies of Context Engineering
While the concept of context engineering may sound abstract, its power lies in a handful of repeatable strategies that shape how information is written, retrieved, and reused. These strategies form the backbone of systems that think in continuity instead of isolated prompts.
The toolkit that transforms "smart outputs" into "smart understanding"
Efficient context engineering hinges on four key strategies: Write, Select, Compress and Isolate.
- Write Context: Actively capture new data, memories, note-taking and feed them into your system. Example: A research assistant agent logging scratchpads while analysing multiple documents, then storing them for future retrieval.
- Select Context: Which pieces matter now? Retrieval systems dynamically bring back the most relevant information. Example: A code assistant fetching wrong functions from an irrelevant repository because selection logic was poor.
- Compress Context: Token budgets matter. Summarization, token pruning and efficient reuse are required. Example: Automatically summarizing a long chat history so the essential parts remain within the model's window.
- Isolate Context: Use multi-agent division for clean reasoning paths. Prevent collisions. Example: A swarm of sub-agents each managing a sub-task, avoiding one agent's memory interference with another.
Inside Context Engineering - The Building Blocks That Make It Work
To truly understand context engineering, it helps to break down its inner layers. Each layer supports the next, turning isolated prompt tricks into a cohesive reasoning system that remembers, retrieves and refines information over time.
1. Prompt Engineering: The starting layer
Even the smartest context-enabled system needs well-crafted prompts; your instructions to the model define behavior. But prompt engineering alone cannot handle multi-turn workflows, memory, retrieval or long-term context.
2. RAG (Retrieval-Augmented Generation)
RAG is a key enabler: you store chunks of knowledge, index them with embeddings, retrieve relevant chunks at runtime and feed them into your context window with the prompt. This turns an LLM into a domain-aware assistant.
3. Memory and State History
Memory systems store user profiles, long-term preferences and past interactions. The context window is what the model "sees" right now. You must decide how to fill it: prompt plus retrieval plus memory summary. Otherwise old history gets trimmed and the model forgets.
4. Context Window: How much the LLM can "see" and how to extend it
The model's token budget is finite. Using longer windows helps, but without smart context engineering you might send a lot of "junk" internal history and push out what matters. You must plan what stays, what goes and when to compress. If an agent starts hallucinating mid-workflow because old messages got trimmed out, that is a context window failure.
Another statistic: enterprises building agentic architectures report that three out of four projects fail when they rely only on prompting and lack proper context management.
Common Context Failures in Real Systems
Before diving into specific examples, it helps to understand why LLMs sometimes derail even in well-designed pipelines. These failures often surface when the model's memory system breaks, when retrieval logic is mis-tuned, or when overlapping contexts compete for attention.
When LLMs stop making sense and why?
- Context Poisoning: When irrelevant, wrong or malicious data enters memory and then gets retrieved, it corrupts your system's reasoning.
Example: a mis-tagged document entering retrievable memory and misleading the LLM. - Context Distraction: Too much irrelevant or stale data in the window makes the model spend tokens reading "junk" rather than meaningful context.
Example: long chains of chat history with nothing pruned. - Context Clash: Conflicting memory or retrieval leads to confusion.
Example: One agent rewrote another's memory without coordination, now the system has contradictory statements.
Real scenario: Multi-agent setup where one agent rewrites another's memory. Imagine two agents, one managing customer profiles and one managing sales history. If both write to the same memory store without validation, you end up with contradictions ("Customer prefers premium plan" vs "Customer downgraded"). That leads the LLM to incoherent output.
How to detect and prevent these pitfalls in production:
You need instrumentation: Dashboards for token usage, hallucination rates, retrieval relevance scores, memory entry counts and context overflow events. At Tericsoft we include monitoring and alerts for memory drift, context window saturation and retrieval mismatches.
Context Engineering for Agentic Systems
Agent-based LLM systems depend heavily on context engineering just as much as they do on good model architecture.
Example flow: Email Al agent learning from your feedback over time Imagine an agent that writes your emails, tracks your responses, learns your tone and preferences and evolves over time.
- Write: Log your tone or preference as you respond.
- Select: Retrieve relevant past threads when drafting new emails.
- Compress: Summarize older threads so they don’t overload the window.
- Isolate: Use sub-agents for subject lines, body content and signature style. Over time the agent becomes personalised, persistent and context-aware, not just a one-shot prompt generator.
Another real scenario: A meeting-assistant agent forgets attendees' preferences after several months because no memory pipeline was built and retained preferences vanish.
Diagram: Agent context loop (Write → Retrieve → Reason → Update) The high-level loop for agentic systems:
- Write: Save new data or memory after each step
- Retrieve: Fetch relevant memory or documents for the next step
- Reason: Use the LLM plus context window plus prompt to generate action
- Update: Write new memory, prune dormant items and compress older ones Context engineering designs and orchestrates that loop.
The Cost of Ignoring Context - Business and Performance Impact
When you ignore context engineering you pay a significant price.
How lack of context inflates API costs and hallucination rates
If your system keeps re-prompting with large irrelevant history, you spend more tokens, crease latency and cost. If the model lacks the correct memory or retrieval, hallucinations increase and you loop, wasting time and budget.
Lost productivity due to re-prompting or misaligned context
Enterprises deploying chatbots or agents for customer service or sales often waste hours because the model asks the user to repeat information. That reduces trust and ROI.
Real scenario: Enterprise chatbot with three times token spend due to redundant retrievals A SaaS enterprise deployed an assistant without context engineering. Because the retrieval system fetched full FAQ logs each time (rather than summarized, relevant fragments) token consumption tripled, latency increased and costs ballooned. After redesigning retrieval and memory summarization the hallucination rate dropped by 40 percent and token usage dropped by 30 percent.
How Tericsoft Builds Context-Aware LLM Solutions
At Tericsoft we help startups, enterprises and technical founders build next-gen agentic, memory-enabled LLM applications. Here's how:
- We engineer with frameworks like LlamaIndex, GPT, Claude and Cohere, deploying RAG pipelines, hybrid search and dynamic prompt plus context optimisation.
- We architect context graphs, hybrid retrieval pipelines and dynamic memory systems (short-term and long-term) so your assistant remembers.
- We build "Super Engineer Al" platforms that orchestrate prompts, context selection, retrieval and memory update, allowing you to move beyond one-shot prompts.
- Target geographies: India, UAE, UK and US serving startup CTOs, enterprise Al architects, prompt engineers evolving into deeper roles and founders seeking context- aware copilots or assistants.
When you choose Tericsoft you are not just selecting a prompt engineer; you are selecting a context architect.
The Future of Context Engineering - Toward Contextual Intelligence
We are transitioning from static prompts to adaptive context to autonomous cognition. Models are expanding context windows and enabling persistent memory across sessions. Context graphs are emerging as the neural interface between humans and machines.
Real scenario: Future agents that auto-prioritise context Imagine an enterprise assistant that automatically decides which memory items to pull, which tools to call, when to compress historical conversation and when to isolate sub- agents, with no manual prompt tweaking. That level of autonomy is coming.
The shift in mindset: you move from "I am a prompt engineer writing clever instructions" to "I am a context architect designing memory, retrieval, workflow and continuity."
Conclusion - Everything Is Context Engineering
To recap, today's LLMs are extremely capable, but they only shine when you give them the right environment. Context engineering is not optional; it's the foundation of real, usable, reliable LLM systems. Prompt engineering still matters, but it lives inside the container that context engineering builds.
When you design your next Al system ask: Does it remember? Does it retrieve correctly? Does it prune and compress? Does it isolate sub-tasks? If you answered "no", you are still relying on prompt engineering alone.
Context Engineering is designing systems that give LLMs the right memory, tools, and data to reason meaningfully.
Prompt Engineering shapes inputs, while Context Engineering builds memory, retrieval, and reasoning across sessions.
LLMs have limited context windows. Once token limits are exceeded, older information gets trimmed or ignored.
It reduces hallucinations, manages memory, and ensures continuity, making AI more consistent and context-aware.
It powers memory-based chatbots, agentic systems, and AI assistants that recall user preferences over time.