






What is Contextual Retrieval and why is it the key to Al that doesn't lie? Learn how RAG gives LLMs long-term memory, stops hallucinations, and finally unlocks your private enterprise data for accurate, secure answers.
We've all seen the magic. Ask a Large Language Model (LLM) to write a poem about a lonely robot, and it delivers a masterpiece. But ask it for last quarter's sales figures or the details of a new compliance rule, and the magic shatters.
This is the central paradox of modern Al. We have built the most powerful reasoning engines in history, but they are static models. They are "experts" locked in a soundproof room, able to reason only with the (aging) library of public web data they were trained on.
To be truly useful to an enterprise, these "experts in the room" must connect to the constant, massive flow of dynamic, proprietary data. They need a secure, reliable connection to your company's "outside world."
The entire industry has rallied around a single solution for this: Retrieval-Augmented Generation (RAG).
At its core, RAG is the "plumbing" that connects the LLM to an external knowledge base. It's the groundbreaking idea that said: "Instead of just asking the LLM a question, let's first retrieve relevant documents from our own database and augment the LLM's prompt with those facts."
But there's a problem. A basic RAG system is "dumb." It's just a simple data fetcher. If you ask, "What was our Q3 sales performance?" , a basic RAG system might just search for the keywords "Q3" and "sales," find 50 different documents, and dump all of them into the LLM's prompt, forcing it to guess which one is correct.
This is where Contextual Retrieval comes in.
If RAG is the plumbing, Contextual Retrieval is the intelligence layer that directs it. It's not just fetching; it's understanding. It deeply analyzes the query's intent ("how did we do" = "financial performance"), finds the single exact snippet of information (the Q3 summary table), validates its relevance, and provides only that curated brief to the LLM.
This is the bridge from a novel technology to an enterprise-grade tool.
What is Contextual Retrieval?
To be precise, Contextual Retrieval is the retriever component of Retrieval-Augmented Generation (RAG) architecture. RAG is the foundational mechanism that connects an LLM to an external knowledge base; Contextual Retrieval is the intelligence that perfects this process.
Standard keyword-based retrieval is a blunt instrument. If an employee asks, "What was our Q3 sales performance?" a simple keyword search for "sales" and "Q3" might return hundreds of documents: old reports, new reports, marketing plans, and email chains. This is a low-precision, high-recall problem. The expert LLM is buried in noise.
Contextual Retrieval moves beyond keywords to understand semantic intent. When a user asks, "How did we do last quarter?" the system infers the intent ("financial performance") and entities ("Q3 2025").
It then navigates the secure knowledge base to find the single, verified Q3 SEC filing or the finalized internal summary, pulls the relevant tables and executive overview, and hands only that to the expert.
This is the profound difference: standard retrieval finds documents that match keywords; contextual retrieval finds answers that match meaning.
Why is this so critical? Because an LLM's base training has zero knowledge of your internal sales data, your recent legal memos, or your specific customer support tickets. A customer support chatbot needs your business-specific policies (anthropic.com). A legal analyst bot needs the most recent case law. Contextual retrieval is the only way to provide this specific, timely, and private knowledge to the LLM, at the exact moment it's needed.
Traditional vs. Neural Retrieval (BM25 vs. Embedding- Based Search)
To understand why contextual retrieval is such a breakthrough, we must first differentiate the two core methods of search.
Lexical (Sparse) Retrieval: BM25 and Keyword Matching
For decades, search was dominated by lexical search, powered by algorithms like Okapi BM25. This is a "sparse" retrieval method, meaning it represents documents based on the specific words they contain (a sparse vector with many zeros). It's a highly evolved version of TF-IDF that excels at matching keywords and term frequency.
It is fast, reliable, and provides high precision for exact-match queries. If you need to find every document containing the specific error code "TS-999," BM25 is your best tool. Its weakness is its complete lack of semantic understanding. It doesn't know "how did the company do" means "financial performance."
Semantic (Dense) Retrieval: Neural Embeddings
This is where semantic search changes the game. It uses "dense" embedding models to read text and convert its conceptual meaning into a rich, high-dimensional vector. In this "vector space," a query and its correct answer are "close" to each other, even if they don't share any keywords.
When you ask, "How did the company do last year?"' the system searches for vectors with semantic proximity, finding documents like "Q4 Earnings Call Transcript" or "Annual Report." This provides high recall for conceptual queries.
Hybrid Search and Rank Fusion: The 'Best of Both Worlds'
Here lies a critical insight for enterprise Al: neither system is a silver bullet. A pure semantic (dense) model might fail to find "TS-999" because the embedding doesn't apture the importance of that specific token. It struggles with acronyms, product SKUs, nd jargon that sparse retrieval catches perfectly.
This is why Hybrid Search is the gold standard. It runs both searches in parallel - lexical search for precision and semantic search for conceptual recall. It then uses a rank fusion algorithm (like Reciprocal Rank Fusion) to intelligently combine the results, ensuring you get both the "needle in the haystack" (the exact keyword) and the "vibe in the haystack" (the conceptual answer).
How Contextual Retrieval Works in LLM Workflows
So, how do we plug this new conceptual library into our "Expert in the Soundproof Room"? This is the RAG pipeline, supercharged with context.
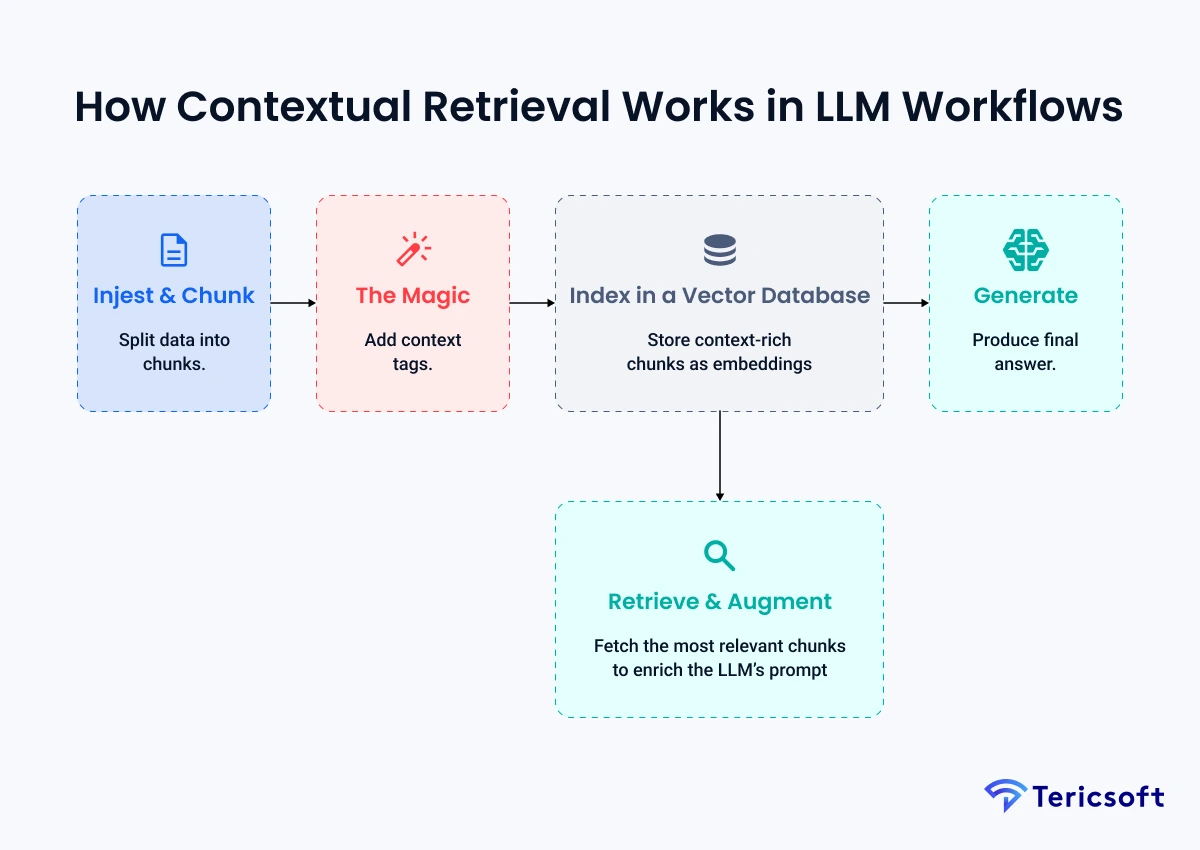
Here is the step-by-step flow:
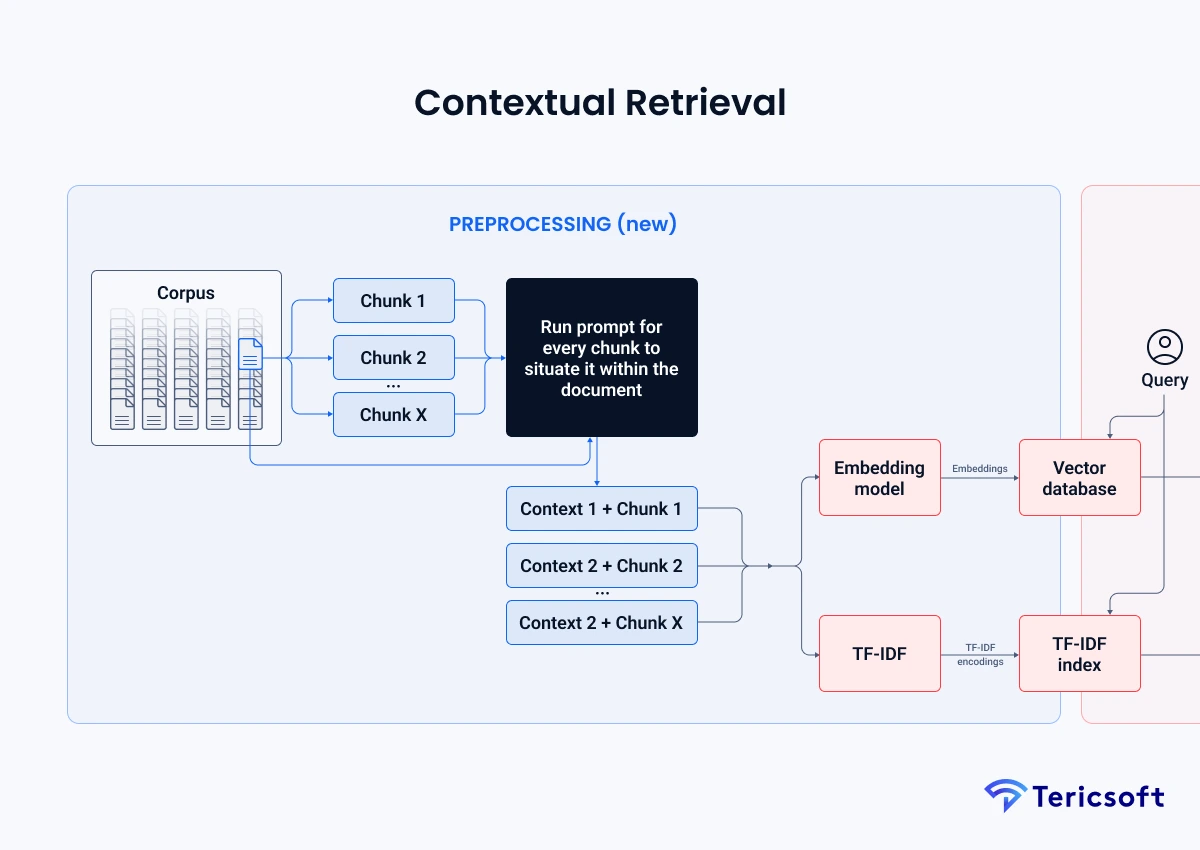
- Ingest & Chunk: First, we take our entire knowledge base - all our reports, articles, and data - and break it into small, digestible paragraphs or "chunks." This "chunking" strategy is a critical first step, as you want chunks to be small enough to be relevant but large enough to contain useful context.
- The "Contextual" Magic: Here's the key. Instead of just embedding the raw chunk, we add a "prep-note" of metadata. As researchers at Anthropic found, this dramatically improves accuracy.
- Bad: Just embedding the text "The profit margin was 5%." (Margin on what? From when?)
- Good: Embedding the text "This chunk is from an SEC filing on ACME Corp Q2 2023, discussing financial performance. The profit margin was 5%." (Now the vector knows what it is).
- Index in a Vector Database: We store these "context-aware" vectors in a specialized, high-speed "conceptual index" known as a vector database. (Think tools like Pinecone, Weaviate, Milvus). This database is built to perform incredibly fast similarity searches across billions of vectors.
- Retrieve & Augment: When a user asks a question, we embed it and find the top 3- 5 most similar contextual chunks from our database. As mentioned, the best systems use a hybrid retrieval approach.
- Generate: We feed these curated, context-rich chunks to the LLM. We preface the prompt with a simple, powerful command: "Using only the information provided below, answer the user's question. Cite your sources."
The LLM (our expert) now has the facts. It's no longer guessing; it's synthesizing an answer grounded in verifiable truth.
A Practical Look at Implementation (The Anthropic Method)
For the Al engineers and technical founders, here's a simplified, conceptual look at how you would implement the "contextual" enhancement popularized by Anthropic, often using frameworks like LangChain or Llamalndex.
# --- 1. Load and Chunk Data ---
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('./your_knowledge_base/')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# --- 2. Generate Contexts (The Anthropic "Magic Step") ---
# This uses a cost-effective LLM (like Claude Haiku or GPT-4o-mini)
# to generate context for *each* chunk based on the full document.
# This is the core of Anthropic's "Contextual Retrieval" technique.
# This is a one-time, offline process.
from langchain.chat_models import ChatOpenAI # Or langchain_anthropic
llm_for_context = ChatOpenAI(model="gpt-4o-mini", temperature=0) # Or ChatAnthropic(model="claude-3-haiku-...")
context_prompt = """
<document>
{full_document_text}
</document>
<chunk>
{chunk_text}
</chunk>
Provide a short, 1-2 sentence context for the chunk based on its place in the full document.
Example: This chunk, from a section on Q2 financial performance, details profit margins.
"""
contextual_chunks = []
for chunk in chunks:
# Find the full doc text chunk belongs to
full_doc_text = chunk.metadata['source_document_text']
# Call the LLM to generate the context
context_str = llm_for_context.invoke(
context_prompt.format(full_document_text=full_doc_text, chunk_text=chunk.page_content)
)
# --- 3. Create Contextual Chunks ---
new_content = f"{context_str.strip()} \n\n {chunk.page_content}"
chunk.page_content = new_content # Overwrite the chunk with its new contextual content
contextual_chunks.append(chunk)
# --- 4. Embed and Index (Vector Search) ---
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embeddings_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = FAISS.from_documents(contextual_chunks, embeddings_model)
# --- 5. Index (Keyword Search) ---
from rank_bm25 import BM25Okapi
# We also index the *same* contextualized text for keyword search
tokenized_corpus = [doc.page_content.split() for doc in contextual_chunks]
bm25 = BM25Okapi(tokenized_corpus)
# --- 6. Create a Hybrid Retriever and RAG Chain ---
# (This part is complex, but in pseudo-code...)
# A real retriever would query both vector_store and bm25,
# then combine and rerank the results.
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm_for_answers = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# The 'retriever' here would be our custom hybrid (vector + BM25) retriever
hybrid_retriever = vector_store.as_retriever() # Simplified for this example
qa_chain = RetrievalQA.from_chain_type(
llm=llm_for_answers,
chain_type="stuff", # "Stuff" means "stuff" all retrieved docs into the prompt
retriever=hybrid_retriever
)
# --- 7. Run Query ---
query = "What was the profit margin in Q2 2023?"
response = qa_chain.run(query)
print(response)
# Output (Grounded in facts):
# "According to the SEC filing for ACME Corp Q2 2023, the profit margin was 5%."Benefits of Contextual Retrieval for AI Applications
This isn't just a technical improvement; it's a business transformation.
- Drastically Reduces Hallucinations: This is the big one. When an LLM is grounded in facts, it can't make them up. One study found that in finance, LLMs hallucinate answers in up to 41% of queries when not grounded in a verified data source. Contextual retrieval fixes this, which is the number one requirement for building user trust.
- Delivers Shockingly Accurate Answers: This method finds the right information. Anthropic's own research showed their Contextual Retrieval method reduced failed retrievals by 49% - and up to 67% with re-ranking. This means users get relevant, precise answers, not just "close" ones.
- Unlocks Enterprise Data (Securely): The LLM never has to be trained on your private data. It just gets tiny, relevant snippets at the moment of the query. This "long-term memory model is a massive win for privacy and compliance. For regulations like GDPR, it's a game-changer, as it keeps sensitive data in-house.
- Improves Efficiency and ROl: For employees, this means faster access to information. For customers, it means instant, accurate answers from a support bot. This translates directly to saved time, higher productivity, and better customer satisfaction.
Limitations and Challenges: What's the Catch?
This sophisticated "new library" isn't a simple upgrade. There are real-world trade-offs to consider:
- Cost & Complexity: Vector databases and embedding models require significant storage and compute power. Indexing millions of documents into vectors is not a trivial task and comes with infrastructure costs. The initial "context generation" step also requires costly LLM calls for every chunk in your database.
- The "Lost in the Middle" Problem & The Need for Reranking: A critical two-part challenge. First, even with perfect retrieval, LLMs struggle to use information buried in the middle of a long context prompt. Research shows LLMs have a strong bias toward information at the very beginning or end, leading to the "lost in the middle" problem. Second, your initial hybrid search might return 20 "good" results, but only 3 are excellent. This is where reranking becomes essential. This second step sorts the retrieved "good" chunks to put the most relevant one at the very top, solving the "lost in the middle" problem and ensuring the LLM sees the best information first.
"Reranking is a crucial technique that can dramatically boost the relevance... By applying more sophisticated relevance judgments to an initial set of candidate documents, reranking helps ensure that the most salient information makes it to the language model"
— Experts at Chatbase
- The Art of Context: How much metadata do you add to each chunk? Too little is useless. But, as some research notes, adding 50-100 extra tokens of context to millions of chunks increases index size, cost, and can potentially add "noise" that confuses the retrieval model.
- The Jargon Problem: Out-of-the-box models might not understand your company's specific, internal jargon. Without fine-tuning the embedding model itself, even advanced neural retrievers can struggle, and old-school BM25 might still win for those niche terms.
- Latency and Token Limits: Every retrieved chunk adds to the token count of the final prompt sent to the LLM. This increases both the cost of the LLM call and the time it takes to get a response. Careful balancing is required.
Tools and Frameworks Enabling Contextual Retrieval
You don't have to build this from scratch. A rich ecosystem of tools is available to build your pipeline.
- Vector Databases (The Shelves): These are the powerful indexes for your vector "library,." Key players include Pinecone, Weaviate, Milvus, Chroma, and the open- source library FAISS - from Meta. The vector database market is already estimated at ~$3 billion and growing ~20% annually, showing how foundational this tech has become.
- Orchestration Frameworks (The Librarians): LangChain and Llamalndex are the "plumbing" that simplifies the entire RAG workflow. As shown in the code example, they provide easy-to-use modules for chunking data, connecting to embedding models, querying vector databases, and constructing the final prompts.
“Vectors are the new language of AI, and vector search bridges the human world and the computational world”
— Ash Ashutosh, CEO of Pinecone
Real-World Use Cases and Examples
This isn't theory; it's already running in the world's top firms, creating tangible value.
Enterprise Knowledge Assistants
The most famous example is Morgan Stanley. Their Al assistant, powered by retrieval, gives financial advisors real-time, precise answers from petabytes of proprietary research. The adoption is staggering: 98% of their advisor teams reportedly use it in their daily workflow. This is the model for internal legal, HR, and finance assistants that can instantly answer questions based on company policy.
Intelligent Agents with Contextual Memory
This is the next frontier. Al agents that can perform complex, multi-step tasks. To book a trip, an agent must retrieve flight options, retrieve your calendar, retrieve hotel policies, and then act. Contextual retrieval is its working memory, allowing it to pull in new facts as it reasons through a problem.
Domain-Specific Chatbots
This is where context is king. A healthcare bot can retrieve a specific patient's chart and the latest medical literature to help a doctor with a diagnosis. A customer support bot can pull up your order history and the exact return policy for that item. This specificity is what provides a trustworthy, expert-level answer.
Conclusion - Why Contextual Retrieval Matters
Contextual retrieval is more than just a feature. It is the critical component that makes LLMs trustworthy, accurate, and relevant enough for the enterprise.
It finally connects our "Expert in the Soundproof Room" to the real-time, proprietary data that businesses run on. It transforms the LLM from a "brilliant amnesiac" into a true "expert assistant" that can reason with your data.
"It is critical that we keep pushing the boundaries of context-aware Al and search"
— Edo Liberty, founder of Pinecone
This is the foundation for the next generation of intelligent, context-aware applications. The future of this technology isn't just "Agentic RAG" , where an Al can reason about what to retrieve. The true horizon is a system that can retrieve, reflect, and even ask clarifying questions - moving from a simple answer engine to a genuine, collaborative problem-solver.
Contextual Retrieval helps AI find data based on meaning, not keywords, delivering precise, fact-based answers to queries.
It adds an intelligence layer to RAG, interpreting query intent and retrieving only the most relevant, verified information.
BM25 matches exact keywords, while neural retrieval uses embeddings to find semantically related answers.
It enables LLMs to use private company data securely, reducing hallucinations and improving accuracy for business applications.
Frameworks like LangChain, LlamaIndex, and vector databases such as Pinecone and Weaviate power retrieval systems.


