






What is Retrieval-Augmented Generation (RAG)? How it enhances LLMs with live, trusted data and how Tericsoft builds secure, enterprise-grade RAG systems for business intelligence and Al accuracy.
A regulator calls your bank's chatbot and asks about a clause that changed last quarter. The bot answers calmly, cites the clause, links the latest PDF, and explains what changed. No panic. No "I am not sure." This is the promise of RAG (Retrieval-Augmented Generation). It lets an LLM reach beyond its frozen training cut-off and ground every response in your live corpus, your policies, your docs, your data lakes. RAG is how modern Al moves from generic text to grounded answers that you can defend in a boardroom.
RAG (Retrieval-Augmented Generation) connects a generative model to external knowledge so answers are accurate, current, and citeable. IBM describes RAG as an Al framework that improves response quality by grounding on external sources.
Source: IBM Research
At Tericsoft, we design enterprise-grade RAG Al systems that integrate 30 plus models across GPT, Claude, Cohere, Mistral, Llama, Qwen, and DeepSeek. We pair hybrid retrieval with memory-driven architectures so your assistants do not just speak. They remember, retrieve, and prove.
Introduction: From generic text to grounded answers
Static LLMs cannot know your latest documents. Their parameters were set at training time. If you ask about a policy updated last week, you risk a confident but wrong answer. RAG adds a retrieval step before generation. The model first searches your trusted knowledge bases, then conditions its reply on those sources, with citations. Cloud and research explainers from multiple vendors define RAG as exactly this design pattern.
“Hallucinations are solvable when models can look things up. Retrieval-Augmented Generation turns a chatbot into a research assistant that gathers evidence first, then summarizes.”
— Jensen Huang, CEO of Nvidia
What is RAG (Retrieval-Augmented Generation)?
RAG (Retrieval-Augmented Generation) is a design pattern that connects a large language model to external knowledge through information retrieval. The LLM generates text that is conditioned on the retrieved passages. This increases relevance, allows citations, and keeps answers current. IBM, AWS, and Microsoft describe RAG in exactly these terms for enterprise solutions.
"This is not just a chatbot, it's a research assistant summarizing for you."
—Jensen Huang, CEO of NVIDIA
Why it matters today?
Policy churn, product updates, and legal risk make static parametric knowledge insufficient. RAG lets you hot-swap sources and update answers without retraining. Wikipedia summaries and vendor docs capture this practical benefit: update the knowledge base, not the weights.
The original 2020 RAG paper showed that combining a generator with a non-parametric memory set state of the art on open-domain QA and produced more specific and factual language than a parametric-only baseline.
Source: Arxiv
How RAG works: Connecting memory to generation, with a live example
Imagine a policy question: "What KYC documents are acceptable for new NRI accounts in 2024." Your RAG architecture executes the following:
Corpus preparation and chunking
Definition. Collect enterprise files. Convert to clean text. Split into semantically coherent chunks that preserve headings and references. Good chunking boosts recall during retrieval. How RAG works in practice starts with well-structured data.
Example. A 500-page policy PDF becomes 800 chunks of 300 to 500 tokens, each storing document title, section ID, and page number.
Embeddings and vector databases
Definition. Run an embedding model over each chunk and store dense vectors in a vector database for nearest-neighbor search.
Example. Every chunk becomes a vector in FAISS, Pinecone, or Weaviate along with metadata for filters like department or effective date. IBM's RAG architecture notes this pattern.
Sparse indexing with TF-IDF or BM25
Definition. Build a keyword index so exact terms and acronyms are not missed. RAG Al is most reliable when dense and sparse retrieval are combined.
Example. Queries that contain "RBI-KYC-2024" are captured by BM25 then merged with embedding results. Microsoft's RAG overview highlights retrieval that incorporates proprietary enterprise content.
Query understanding and retrieval
Definition. At runtime the user query is embedded and matched against the vector index. In hybrid retrieval, BM25 results are fetched in parallel and merged.
Example. "What KYC documents are acceptable for NRI accounts" returns eight chunks. Five come from dense similarity. Three come from BM25 because they contain "NRI KYC" exactly.
Rank fusion and reranking
Definition. Merge dense and sparse lists, then apply re-ranking to order chunks by semantic relevance and recency before sending to the model.
Evidence. Anthropic's research on Contextual Retrieval reports up to 49 percent fewer failed retrievals, rising to 67 percent when combined with reranking.
Prompt augmentation and grounded generation
Definition. Compose a prompt that includes the user question plus the top K chunks. The RAG Al model generates an answer constrained by those sources and returns citations. AWS explains RAG as referencing an authoritative knowledge base outside the model's training data.
Example. The assistant replies with a short answer and bullet references like "Source: KYC circular 2024-17, section 3b."
Optional verification and feedback
Definition. Add citation verification, answer grading, and user feedback capture. Store failed answers to improve chunking and retrievers over time.
Example. If users downvote an answer, the pipeline logs the query and the retrieved chunks so you can adjust chunk sizes, add recency boosts, or refine filters.
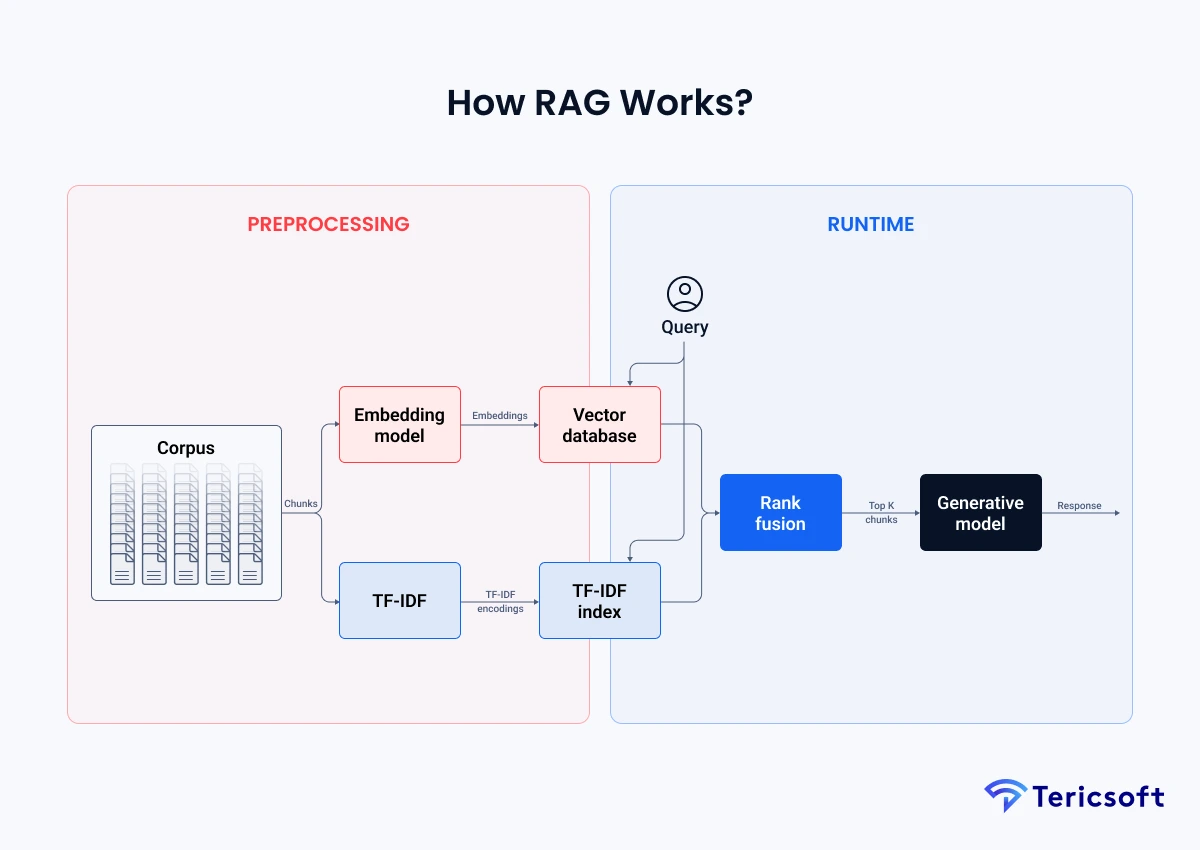
RAG architecture: Building blocks that make it reliable
Think of your RAG architecture as five layers that each do one job well.
- The embedding layer
Maps passages to dense vectors so you can find conceptual neighbors. IBM's RAG pattern documentation emphasizes this as the first mile of retrieval. - Vector databases
FAISS, Pinecone, or Weaviate store vectors and metadata for fast queries. AWS prescriptive guidance shows a typical high-level RAG layout used in enterprises. - Rank fusion and reranking
Merge dense and sparse results, then promote the most relevant and recent chunks. Anthropic's contextual retrieval results quantify the gains. - Generative model integration
Send the selected passages to the LLM and instruct it to answer with citations. Microsoft Learn highlights that you can constrain generation to enterprise content for governance. - Orchestration and observability
Tie it all together. Track retrieval precision, groundedness rate, and latency. Update indexes on a schedule so your RAG Al stays fresh.
Nvidia’s public guidance frames RAG as giving models sources they can cite like footnotes so users can check claims. This is precisely the trust lever regulated businesses need.
Source: NVIDIA Blog

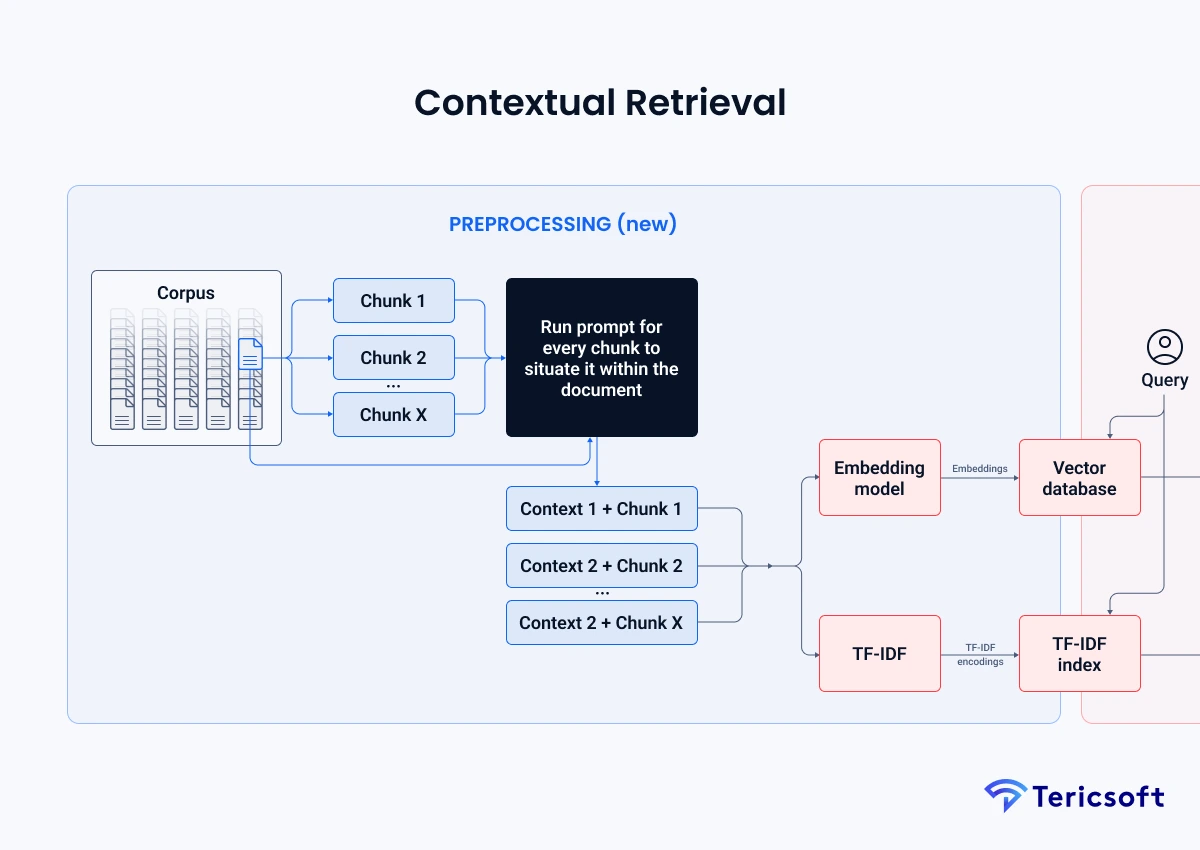
Contextual retrieval: Upgrading recall and precision
Basic retrieval can still fail on short, ambiguous queries or acronym-heavy text. Contextual retrieval enriches both embeddings and BM25 with local context before indexing. Anthropic reports that contextual approaches reduce failed retrievals by 49 percent, and by 67 percent when combined with reranking. That is a large lift for enterprise RAG Al where one wrong clause can cost money.
"This is not just a chatbot. It is a research assistant summarizing for you."
—Jensen Huang, CEO of NVIDIA
Applications of RAG: Real enterprise use cases
RAG isn't just an academic idea, it's already transforming how enterprises operate. By connecting LLMs with proprietary knowledge sources, businesses are achieving more reliable, contextual, and auditable Al systems. Here are some of the most impactful applications of Retrieval-Augmented Generation in the real world:
- Internal knowledge assistants
Policy and procedure Q&A with provenance so auditors can verify claims. Multiple vendors describe RAG as enabling grounded answers over proprietary content. - Legal and compliance copilots
Surface the latest clauses and rulings. Rank recent circulars above archived ones. Anthropic's retrieval work is especially helpful in precedence-sensitive domains. - Healthcare and life sciences
Retrieve guidance, dosage tables, or trial summaries with citations. IBM explains that RAG helps LLMs produce factually correct outputs for specialized topics beyond training. - FinTech and banking
Answer product terms and regulatory questions with page-level sources. Microsoft Learn emphasizes constraining generation to enterprise content for safety. - Customer support deflection
Ground replies in manuals and tickets to reduce escalations. AWS's RAG pages outline exactly this pattern.
Implementation of RAG: From pilot to production
Data ingestion and governance. Pull from SharePoint, GDrive, S3, Confluence, and databases. Normalize formats. Redact PII. Apply access control tags so retrieval respects permissions. IBM's RAG pattern discusses processing content into searchable vector formats.
Retrieval choice. Dense only is fast but can miss acronyms. Sparse only is brittle on paraphrases. Hybrid retrieval wins in the enterprise where language is messy. Anthropic's contextual retrieval results quantify hybrid plus reranking benefits.
Evaluation. Track retrieval precision and recall. Measure groundedness and citation validity. Keep latency budgets realistic so RAG Al stays usable. AWS prescriptive guidance gives a high-level evaluation flow.
Operations. Refresh embeddings regularly. Prefer incremental indexing to full rebuilds. Add caching for frequent queries. Observe drift in both content and questions.
"RAG lets you update answers by updating the knowledge base rather than retraining a model. That is how teams keep systems fresh without expensive fine-tunes. "
Source: Wikipedia
RAG vs Fine Tuning vs Agentic Al
As organizations mature their Al adoption, they often wonder: should we retrieve, fine-tune, or orchestrate agents? These three strategies serve different goals and often work best together. Here's how to decide which approach fits your use case.
- When to use RAG
You need freshness, provenance, or to respect access controls. RAG retrieves and cites. It is how you answer sensitive questions with confidence. AWS and Microsoft position RAG for this enterprise need. - When to fine tune
You want the model to follow your tone, format, or domain-style even without retrieval. Fine tuning adapts behavior when the facts are relatively stable. The original RAG paper argued that retrieval plus generation produced more factual language than a parametric-only baseline, which is one reason teams mix both. - When to build agentic systems
You have multi-step tasks that require tools and planning like search, calculators, and file operations. Agentic flows often still use RAG Al to fetch facts at each step. IBM's recent resources on Agentic RAG capture this combined trend.
Difference table at a glance
“Your model doesn’t need to know everything, it just needs to know how to find it.”
— Sam Altman, CEO of OpenAI
Generative Al and LLM: Where RAG fits in the stack
LLMs are brilliant pattern learners yet struggle with hidden assumptions. RAG (Retrieval- Augmented Generation) reduces reliance on parametric memory by bringing in context from live sources. IBM and AWS are explicit: RAG augments the LLM with external knowledge so it can answer more accurately for domain tasks.
"The entire world could be footnotes that you can investigate if you want." Patrick Lewis, a coauthor of the RAG paper and ML director, uses this framing to explain why citations build trust.
Source: NVIDIA Blog
RAG does not make models "remember" forever. It makes them retrieve the right context each time. That is the safer path for enterprise knowledge systems.
How Tericsoft Builds RAG Systems That Enterprises Trust
At Tericsoft, we design RAG architectures that are enterprise-grade from day one. Our approach focuses on reliability, interpretability, and security so your Al does not just generate, it understands and justifies every answer.
We combine advanced Al orchestration with contextual retrieval and scalable infrastructure to deliver precision at production scale. Here's how we make it work:
- Private RAG Deployments
Built with frameworks such as LangChain and Llamalndex, our RAG stacks are hardened for production environments and customized for private enterprise data systems. - Multi-Model Orchestration
We integrate and optimize across multiple LLMs including GPT, Claude, Cohere, Mistral, Owen, DeepSeek, and Llama, allowing teams to select the best model for each task and budget. - Vector Storage and Hybrid Search
We use FAISS, Pinecone, and Weaviate for dense and sparse hybrid retrieval that scales efficiently while maintaining low-latency responses. - Contextual Retrieval and Reranking
Our pipelines include dynamic context enrichment and reranking strategies so the most relevant passage wins at the right moment. Techniques inspired by Anthropic's contextual retrieval research are part of our playbook for grounding accuracy. - Enterprise Security and Evaluation
Every deployment includes dashboards for groundedness scoring, citation validation, and latency monitoring, ensuring transparency and measurable trust. - Agentic Integration
When workflows require reasoning or tool use, we embed agentic layers that allow systems to plan, search, and act within governed boundaries.
“The goal is not just to build smarter AI, but more trustworthy AI.”
— Abdul Rahman Janoo, CEO of Tericsoft
The Future of RAG: Toward self-updating context graphs
Since 2020, the research signal has been consistent. The original RAG recipe combined parametric models with non-parametric memory and achieved state of the art. The next wave is contextual retrieval, memory fusion, and real-time index refresh so assistants keep pace with your business. Nvidia, IBM, AWS, and Microsoft continue to publish
guidance because adoption is moving from labs to line-of-business systems.
"The next frontier of intelligence is not bigger models, it's smarter context."
— Sundar Pichai, CEO of Google
Conclusion: RAG helps LLMs use your knowledge responsibly
RAG (Retrieval-Augmented Generation) is not a feature. It is a governance choice. It lets you connect LLMs to the right sources, retrieve the right passages, and generate answers you can trust with citations. RAG does not try to make a model remember everything. It makes the model look things up responsibly.
If you need an assistant that is accurate, current, and defensible, RAG Al is your path. If you need that assistant to live inside your compliance and security lanes, Tericsoft is your partner.
RAG connects LLMs to external data sources, enabling accurate, current, and citeable AI responses.
By retrieving verified information before generation, RAG reduces hallucinations and grounds AI answers in facts.
RAG uses embeddings, vector databases, hybrid retrieval, reranking, and generation with citations.
RAG updates knowledge through live retrieval, while fine-tuning changes model weights for fixed data.
It ensures AI assistants provide compliant, trusted, and up-to-date answers using your private data sources.


