






What is Fine-Tuning in Al? Its mechanics and benefits, and how this process transforms general LLMs into domain-specific experts for your business.
Large Language Models (LLMs) like GPT-4 and Llama 2 represent a powerful new baseline for enterprise applications. Their strength is their vast general knowledge, trained on a massive corpus of public data. Their fundamental limitation, however, is this very generality.
When applied to high-stakes, specific domains: like internal legal review, compliant financial advice, or brand-specific customer support: generic model performance falters. They lack proprietary context, "hallucinate" answers that erode trust, and cannot speak in a consistent, controlled brand voice. This creates a critical gap between a general-purpose tool and a high-value, reliable enterprise asset.
To bridge this gap, the essential engineering process is Fine-Tuning.
Fine-Tuning is the discipline of adapting a pre-trained model by retraining it on a smaller, curated set of your own domain-specific data. It is the method for permanently embedding your company's expertise and playbook into the model's core logic. The results are transformative: domain-specific accuracy rises, hallucinations can be cut by over 90%, and the Al shifts from a "smart assistant" to a "digital expert."
This technique works by fundamentally changing the model's weights, not just guiding its output with a prompt. It's the difference between giving an Al a temporary script and permanently teaching it to think like your most experienced employee.
In this post, we'll explore the mechanics, types, and benefits of fine-tuning. We'll also lay out a strategic framework for how organizations can leverage this process to build and deploy precise, compliant, and proprietary Al systems.
What Is Fine-Tuning a Model? (The Foundation)
At its core, Fine-Tuning is the precise, surgical process of taking an existing pre-trained foundation model (like GPT-4 or Llama 2) and retraining it on a smaller, specialized dataset. This dataset is your data: your support tickets, your legal documents, your brand guidelines, your code repository.
It is fundamentally a process of adaptation. Instead of teaching a model to understand language from scratch, you are teaching an already-intelligent model to understand your specific context, terminology, and desired tone.
This approach has become the enterprise standard over building from scratch for several key reasons:
- Lower Cost & Compute: It requires a fraction of the computational power and data.
- Faster Time-to-Value: It delivers a specialized, high-performing model in days or weeks, not months or years.
- Leverages General Intelligence: It builds upon the billions of dollars of research already invested in the base model, so you don't lose its vast world knowledge.
- Easier Governance: It allows for more controlled, auditable, and private deployments, especially when using open-source models.
"If pre-training gives an Al its general intelligence (1Q), fine-tuning gives it your company's specialized expertise and emotional intelligence (EQ)."

What Is LLM Fine-Tuning ? (The Enterprise Focus)
For enterprises, the focus is squarely on LLM Fine-Tuning. This is the process that teaches a large language model to communicate with the specific nuance, terminology, and accuracy required by your business.
It's the difference between an Al that sounds smart and one that is genuinely useful. The surge in interest is palpable; search interest for LLM fine-tuning has grown 2.8x in the last year. Why? Because while prompt engineering is a temporary guide, fine-tuning is a permanent upgrade. It imbues the model with context retention and brand alignment at its very core.
Consider the transformation:
- Generic Chatbot: "Based on general policy information, your plan might cover this type of damage."
- Fine-Tuned Chatbot: "I've reviewed your policy. Under Clause 14a of your 'PremierPlus' plan, your $500 deductible resets on July 1st. This claim is fully covered."
" This is the moment an AI stops giving an answer and starts giving your answer.”
When General-Purpose Models Fall Short (And How Fine-Tuning Fixes Them)
The failure of generic Al in high-stakes environments isn't a failure of intelligence; it's a failure of context.
1. Lack of Domain Context: A model trained on the public internet has no knowledge of your internal logic, proprietary terminology, or confidential case history. It doesn't know your product names, your engineering practices, or your legal precedents. Fine-tuning injects this proprietary knowledge directly into the model's "brain."
2. Hallucinations and Accuracy Gaps: Generic LLMs are notorious for "hallucinating", inventing plausible-sounding but incorrect facts. Research shows this happens 17% of the time. For a legal, medical, or financial application, this is an existential risk. Fine-tuning on a verified, curated internal knowledge base grounds the model in fact, tethering its answers to your reality and reducing hallucinations by over 90%.
3. Model Drift: The world changes, and so does your business. A model trained on 2023 data doesn't know about your 2024 product launch or new compliance rules. Models degrade; some studies show 91% exhibit performance degradation within 12 months. Fine-tuning is not a one-time event; it's a continuous process that keeps your Al aligned with current reality.
"Al doesn't fail because it's dumb, it fails because it's uninformed. Fine-tuning is the process of informing it."
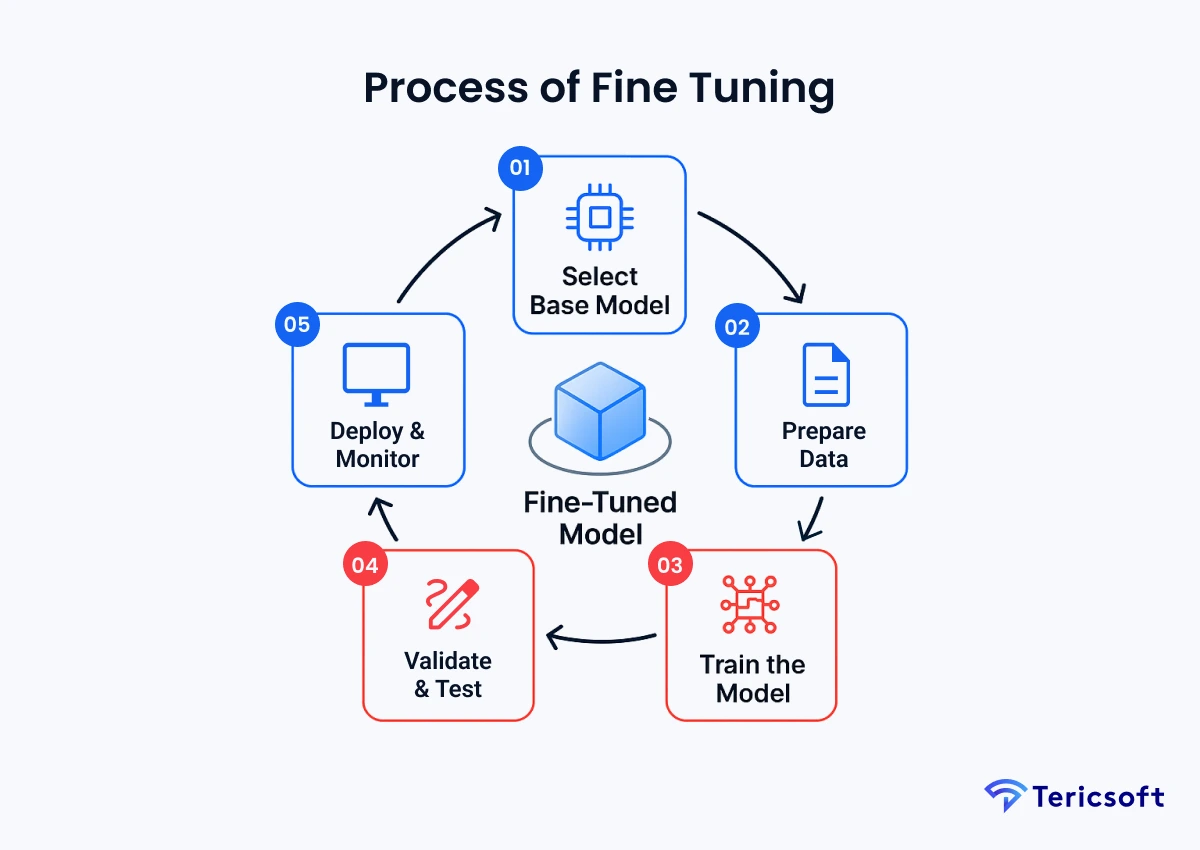
Understanding the Fine-Tuning Process
Fine-tuning is not a single action but an iterative, disciplined engineering loop: Data → Train → Test → Deploy → Refine.
- Select a Base Model: The choice between a closed model (like GPT-4) or an open-source model (like Llama 2 or Mistral) depends on your specific needs for privacy, cost, and scale. Open-source models are increasingly favored for fine-tuning as they can be hosted in your own private cloud, ensuring no proprietary data ever leaves your control.
- Prepare High-Quality Data: This is the most critical and labor-intensive step. Curation trumps volume. A small, clean, meticulously labeled dataset of 1,000 high-quality examples will outperform a "noisy" dataset of 100,000. This process involves:
- Cleaning: Removing formatting errors, HTML tags, and duplicates.
- Anonymization: Redacting or masking all Personally Identifiable Information (PIl) and sensitive commercial data.
- Labeling: Structuring the data into clear "prompt" and "response" pairs, often with the help of your own domain experts.
- Bias Checking: Actively auditing the data for existing biases and augmenting it with counter-factual examples to ensure fairness.
- Train the Model (Carefully): The model is retrained on this new data. The key is to use low "learning rates." A high learning rate would cause "catastrophic forgetting," where the model absorbs the new information but forgets its vast, valuable general knowledge. A low, slow rate carefully "blends" the new expertise without overwriting its core intelligence.
- Validate and Test: The newly tuned model is benchmarked against a "holdout" set of data it has never seen. This isn't just a pass/fail test; it's a rigorous evaluation of accuracy, tone, and resistance to hallucinations on the real-world queries your users will actually make.
- Deploy and Monitor: Once validated, the model is deployed into a production environment. Continuous monitoring via dashboards is crucial to track performance, catch model drift, and create automated feedback loops that identify new, real-world examples to use in the next round of tuning.
Types of Fine-Tuning: Approaches & Trade-offs
This training process isn't monolithic. Modern Al engineering offers a spectrum of approaches, allowing organizations to balance performance with cost.
- Full Model Fine-Tuning: The "classic" approach. All of the model's billions of parameters are updated. This offers maximum control and accuracy, making it ideal for high-stakes domains like medicine or law where precision is non-negotiable. However, it carries the highest computational cost and requires significant GPU resources.
- Parameter-Efficient Fine-Tuning (PEFT): The modern standard for most enterprises. This family of techniques, most famously LoRA (Low-Rank Adaptation), is brilliant in its efficiency. Instead of updating billions of parameters, LoRA "freezes" the original model and adds tiny, trainable "adapter" layers (often ‹1% of the total parameters).
- This drastically cuts compute costs and training time.
- It allows you to train multiple adapters for different tasks (e.g., one for sales, one for support) that all run on top of the same base model, making it incredibly flexible.
- A popular variant, QLoRA, further compresses the model to run on even less VRAM, making it possible to fine-tune massive models on a single, commodity GPU.
- Instruction / Prompt Fine-Tuning: This is less about teaching the model new knowledge and more about teaching it new behavior. By training the model on a dataset of high-quality instructions and desired responses (e.g., "Summarize this, "Translate this," "Act as a helpful assistant"), you align its output style to be more useful, polite, and follow directions reliably.
- Reinforcement-Based Fine-Tuning (RLHF): This is about aligning the model with human preferences. Instead of just "correct" answers, this method uses human feedback (ranking different model outputs from best to worst) to teach the model how to answer: to be more helpful, harmless, and contextually appropriate.
"PEFT and LoRA have made fine-tuning a lightweight add-on, not a heavy-weight luxury. There is no longer a cost barrier to specialization."
Why Your Data Governs Your Al's Performance
The fine-tuning revolution has shifted the strategic focus from model parameters to data quality. Your results will never be better than the data you use to train them.
"You don't need more parameters, you need better examples."
This elevates Data Governance from a compliance checkbox to a core strategic function. A robust governance framework is the prerequisite for trustworthy Al.
- Ethical Sourcing & Bias Mitigation: Where did your data come from? Is it representative of all your users, or does it over-represent one group? Proactively auditing for and mitigating bias is essential to prevent the Al from scaling discriminatory patterns.
- Privacy & Security: Fine-tuning on proprietary data demands a secure-by-design approach. This means rigorous data anonymization and redaction before training, and ensuring the entire fine-Tuning process happens in a secure, isolated environment (like a Virtual Private Cloud) where your data is never exposed.
- A-B Testing: Does your fine-tuned model actually perform better? The only way to know is to rigorously test it against the base model and other variants. This establishes a clear, data-backed ROI.
Insight: Most leaders see data governance as a defensive shield for compliance. In the age of Al, it becomes a strategic-enabling sword. A well-governed, clean, and accessible data pipeline is the single greatest accelerator for building high-performing, proprietary Al.
Fine-Tuning vs. Prompt Engineering vs. RAG
Many organizations are rightly confused about where fine-tuning fits with other popular techniques. Here's the clear distinction:
- Prompting is like giving a smart employee temporary instructions for a new task.
- RAG is like giving them access to a filing cabinet (vector database) to look up facts.
- Fine-Tuning is like sending them to graduate school to permanently embed that new expertise.
For a truly robust enterprise system, these are not mutually exclusive. The most powerful Al systems often combine them: Fine-tuning to teach the model your domain language and workflows, and RAG to provide it with real-time, up-to-the-minute data.
Fine-Tuning vs. Training: Understanding the Foundational Difference
With a clear definition of fine-tuning, it's crucial to distinguish it from its far more costly sibling: training from scratch.
- Training (from scratch) is the monumental, resource-intensive process of building a foundation model from zero. It involves feeding the model billions or even trillions of data points from the open internet to teach it language, reasoning, and general world knowledge. This is the realm of hyperscalers and Al research labs.
- Fine-Tuning (what we just defined) focuses on adapting one of these existing pre- trained models. It uses a much smaller, curated dataset to teach the model your specific language, context, and workflows.
This difference is the key to enterprise adoption:
The Measurable Benefits of Fine-Tuning (Enterprise Impact)
When executed correctly, fine-tuning delivers tangible, compounding ROl.
- Accuracy and Contextual Relevance: The model stops guessing and starts interpreting intent, speaking your industry's language precisely.
- Reduced Hallucinations and Risk: By grounding the model on verified internal data, error rates and compliance risks plummet.
- Brand Consistency and Compliance: Every Al-powered touchpoint, from marketing copy to support emails, perfectly mirrors your brand voice and policies.
- Efficiency and Cost Optimization: This is a crucial, often-overlooked benefit. A fine-tuned, smaller, open-source model (e.g., Llama 3 8B) can often outperform a massive, generic model (like GPT-4) on a specific task, leading to 60-80% lower operational and inference costs.
- Competitive Edge and Proprietary IP: A generic model is a commodity. Your fine-tuned model, trained on your unique data, becomes a proprietary intellectual asset: a strategic moat that compounds in value.
"Your model is your new IP. Protect it, tune it, and let it compound."
Building Your Fine-Tuning Strategy
A successful strategy is methodical, not monolithic.
- Identify High-Impact Use Cases: Don't try to boil the ocean. Start with a defined, high-value task like a customer support bot, a legal summarization tool, or an internal code-review Al. The goal is a clear, measurable win.
- Gather and Label Quality Data: Engage your domain experts. A small, clean dataset curated by your best people is the key. This is the 80% of the work that defines 100% of the success.
- Pick the Right Tech Stack: Decide between the convenience of APIs (OpenAl, Anthropic) and the control of open-source (Llama, Mistral) on a private cloud. For enterprise-grade control and data privacy, an open-source, self-hosted strategy is often the clear winner.
- Pilot, Measure, Scale: Launch a pilot. Track accuracy, tone, and latency gains relentlessly. Use this data to build the business case for scaling the initiative.
Insight: The primary challenge in fine-tuning is rarely the technology; it's organizational alignment. The bottleneck is creating the high-quality data, which requires buy-in from legal, compliance, and subject-matter experts. A successful strategy is as much about data pipelines and people as it is about Python.
While the process is disciplined, it has challenges. Overfitting (losing general knowledge), data quality issues, and governance are real risks. This is why partnering with an experienced Al engineering team is crucial: to navigate these pitfalls and accelerate time- to-value.
The Road Ahead From Fine-Tuning to Adaptive Al
Fine-tuning is the critical first step toward the true future of enterprise intelligence: Adaptive Al.
Gartner lists Adaptive Al as a top strategic trend, defining it as systems that can self-learn and update in real time. The continuous fine-Tuning loops you build today (monitoring drift, capturing user feedback, and retraining) are the foundational architecture for these future self-learning systems.
But what if this process could be truly continuous? This is the vision behind next- generation concepts like Liquid LLMs.
Instead of periodic retraining, a "liquid" model architecture would be designed for constant, real-time adaptation. It would be a system that learns from new data in micro- batches, effectively "improving itself overnight." This approach, inspired by new research into liquid neural networks, promises to solve the model drift problem at its core, creating a truly responsive Al that learns as your business evolves, 24/7.
This is how we move from static models to dynamic, learning organisms. The disciplined fine-tuning strategies of today are building the runway for the "always-on" adaptive models of tomorrow.
Conclusion: The Future Belongs to Custom Al
In the new Al race, everyone starts with the same models. The winners will be the organizations that move beyond generic experimentation and embrace deep, strategic customization.
The future of your business will not be run by a generic Al that knows a little about everything. It will be powered by a fleet of custom, fine-tuned models that know everything about your business, your customers, and your data.
The time to move from "what can Al do?" to "what can Al do for us?" is now. The tool to make that happen is fine-tuning.
Fine-tuning retrains a pre-trained model on your domain data to improve accuracy, reduce hallucinations, and reflect brand voice.
It adds proprietary knowledge, boosts accuracy, reduces risk, and transforms generic AI into a context-aware business expert.
Prompting guides output temporarily, RAG fetches external data, but fine-tuning rewires the model to think like your experts.
Benefits include fewer errors, brand alignment, compliance readiness, faster responses, and lower long-term inference costs.
When tasks require domain accuracy, compliance, security, or scaling support bots, legal tools, or customer-facing systems.


