






How do LLM + RAG architectures secure financial operations? Learn how they unify data silos, eliminate hallucinations, and deliver regulator-ready Al platforms using ten strategic, production-grade deployment patterns.
The financial services landscape is currently undergoing a structural pivot, one defined by a shift from the novelty of artificial intelligence to the necessity of architectural resilience. For the past eighteen months, the narrative surrounding Large Language Models (LLMs) in FinTech was dominated by the "wow factor." We saw experimental chatbots that felt like magic. However, as the industry moves from sandbox environments to mission-critical infrastructure, that "magic" is being replaced by the cold, hard reality of operational risk.
Strategic leaders across the financial sector are no longer asking if they should use LLMs; they are asking how to build them so they don't break the bank or the brand. In this sector, a single "hallucination" isn't just a technical glitch; it is a potential multi-million dollar regulatory fine and a catastrophic breach of fiduciary duty. This reality has established Retrieval-Augmented Generation (RAG) not as a "feature," but as the definitive backbone of modern FinTech. RAG ensures that every Al output is grounded in verifiable, real-time data, transforming a probabilistic engine into a deterministic, audit-ready operational tool.
Why FinTech Operations Are Rethinking Al Architecture
Before deep-diving into the technical blueprints, we must understand the fundamental shift in the FinTech psyche. Al is no longer viewed merely as a tool for hyper-scaling, but as a challenge in maintaining data quality, lineage, and sovereign control. The industry is moving away from superficial Al implementations toward deep, structural integration. This rethinking is driven by the realization that in high-stakes finance, the cost of a mistake isn't just a bad user experience: it is an existential threat.
The shift from chatbots to mission-critical Al systems
We have officially entered the "Second Wave" of Generative Al. The first wave was about the interface, putting a chat box on a website and hoping for the best. The second wave is about integration: embedding intelligence into the high-frequency workflows of banking, lending, and fraud detection. Mission-critical systems cannot afford the "black box" nature of standalone LLMs; they require an architecture that justifies its logic with raw data evidence, turning Al from a novelty into a core business asset.
Why FinTech cannot rely on "prompt engineering" alone
Prompt engineering is essentially trying to "persuade" an LLM to behave. In the world of finance, persuasion is not a security control. No matter how elegantly you phrase a prompt, an LLM lacks access to your real-time ledger or the regulatory circular published ten minutes ago. Architecture, not wording, is what provides the guardrails necessary for institutional stability and regulatory compliance. Relying on prompts for data governance is a fundamental risk that modern architectures seek to eliminate.
The operational cost of Al mistakes in financial systems
An incorrect Al response in a general chat is an inconvenience. An incorrect Al response in an AML investigation or a credit risk assessment is a "hallucination tax" that can trigger a regulatory audit and damage a brand's reputation for decades. This represents an unquantifiable brand risk and a catastrophic failure in data provenance. Architecture is the insurance policy against this tax, ensuring that automated decisions are as defensible as those made by human experts.
Why LLM + RAG architectures have become the backbone of modern FinTech ops
By decoupling the "reasoning" (LLM) from the "knowledge" (RAG), FinTechs gain a system that is transparent, updatable, and secure. This modularity allows institutions to maintain strict control over the knowledge base while retaining the flexibility to swap LLM providers as the market evolves. It ensures that the firm's intellectual property remains within its control, preventing vendor lock-in and safeguarding sensitive data.
Why LLM + RAG is exploding in FinTech operations?
The move toward RAG-centric operations isn't just about accuracy; it is about reclaiming operational control. In a world where financial data moves at the speed of light, static models are obsolete the moment they finish training. By implementing RAG, FinTech operations can solve long-standing friction points while satisfying the stringent demands of global regulators and the strategic growth goals of the organization.
The real FinTech ops problems LLMs solve
By grounding the intelligence of an LLM in the specific context of a financial institution's internal data, RAG transforms Al into a high-utility tool for margin improvement and data utility:
- Manual compliance research: Traditionally, compliance officers are buried under mountains of shifting global circulars, a soul-crushing race against time. RAG automates this by instantly surfacing relevant clauses and identifying contradictions.
- Slow fraud investigations: Analysts often navigate a "data swamp" of transaction logs and identity systems. RAG synthesizes these disparate signals into a coherent, actionable narrative in seconds, accelerating critical decision-making.
- Knowledge silos across teams: Institutional wisdom is often trapped in legacy documentation and abandoned communication threads. RAG unifies this "dark data" into a queryable digital nervous system, preserving the firm's intellectual capital.
- High dependency on human analysts: By shifting from manual retrieval to high- level verification, teams can handle 10x volumes without the burnout that leads to human error or the need for a linear increase in headcount.
- Reactive instead of proactive operations: RAG monitors transaction patterns against historical "lessons learned," flagging risks before they become headlines, effectively protecting the firm's balance sheet and reputation.
Why RAG Is Mandatory in Financial Al Systems
In a highly regulated sector, the burden of proof is always on the institution. Standard LLMs operate on probability, which is the antithesis of the deterministic requirements of financial auditing. RAG is the only way to ensure data lineage in an Al-driven world. It is mandatory because it provides three indispensable layers of protection:
- Static LLM knowledge vs real-time financial data: An LLM's weights are frozen at training. FinTech data changes every millisecond. RAG is the bridge to the "now," ensuring decisions are based on the latest market conditions.
- Traceability and source grounding: In an audit, "because the Al said so" is an admission of failure. RAG ensures every statement is anchored to a verifiable document, providing an immutable audit trail.
- Audit-ready Al responses: Citations are the bedrock of "explainability" requirements. RAG provides the transparent documentation that regulators and internal risk committees demand.
What is RAG in FinTech? (Beyond the Generic Definition)
While the general tech community views RAG as a way to improve Al performance, in FinTech, it is viewed as a security and governance framework. RAG is the control plane for Al. We define RAG not just as a retrieval mechanism, but as a "permission-aware" intelligence layer that bridges the gap between raw language processing and institutional security protocols.
FinTech-specific definition of Retrieval-Augmented Generation
In FinTech, RAG is a secure pipeline that retrieves only permissioned, context-specific data to augment the reasoning capabilities of an LLM. It is the transition from "General Intelligence" to "Firm-Specific Expertise."
Difference between consumer RAG and regulated RAG
Consumer RAG is about finding the "closest" answer. Regulated RAG is about finding the authorized answer. It respects the invisible but iron-clad boundaries of data sovereignty and cross-border data restrictions.
Why FinTech RAG requires policy, identity, and permission awareness
If an Al retrieves a sensitive client credit report to answer a general query from an unauthorized employee, the system has failed. This is more than a technical error; it is a privacy breach and a failure of access control. Security and permissions are the foundation of the retrieval logic, not an afterthought.
The FinTech RAG data layer
A RAG system is only as good as its data layer. To build a regulator-ready system, we must move beyond simple document ingestion. The architecture must harmonize a diverse array of high-velocity and high-sensitivity data streams to create a "Single Version of Truth" for the Al era:
- Internal policy documents: The "laws" of the company, underwriting and SOPs.
- Transactional databases: The "ledger," the ground truth of customer activity.
- Case management systems: The "memory," context from previous investigations.
- AML rules and regulatory circulars: The "external world," live feeds from FINRA, SEBI, or the ECB.
- Logs, alerts, and historical incidents: Technical telemetry for troubleshooting.
Architecture Insight: In FinTech, data selection and curation matter significantly more than model choice. A superior retrieval pipeline using a smaller model will consistently outperform a generic GPT-4 deployment that lacks a permission-aware data layer.
Best LLM + RAG Architectures for FinTech Operations
The "one-size-fits-all" approach to Al is the primary cause of project failure in the enterprise. Each financial operation requires a specific architectural blueprint to balance accuracy, latency, and security. We have identified the following ten architectures as the gold standard for modern FinTech deployments.
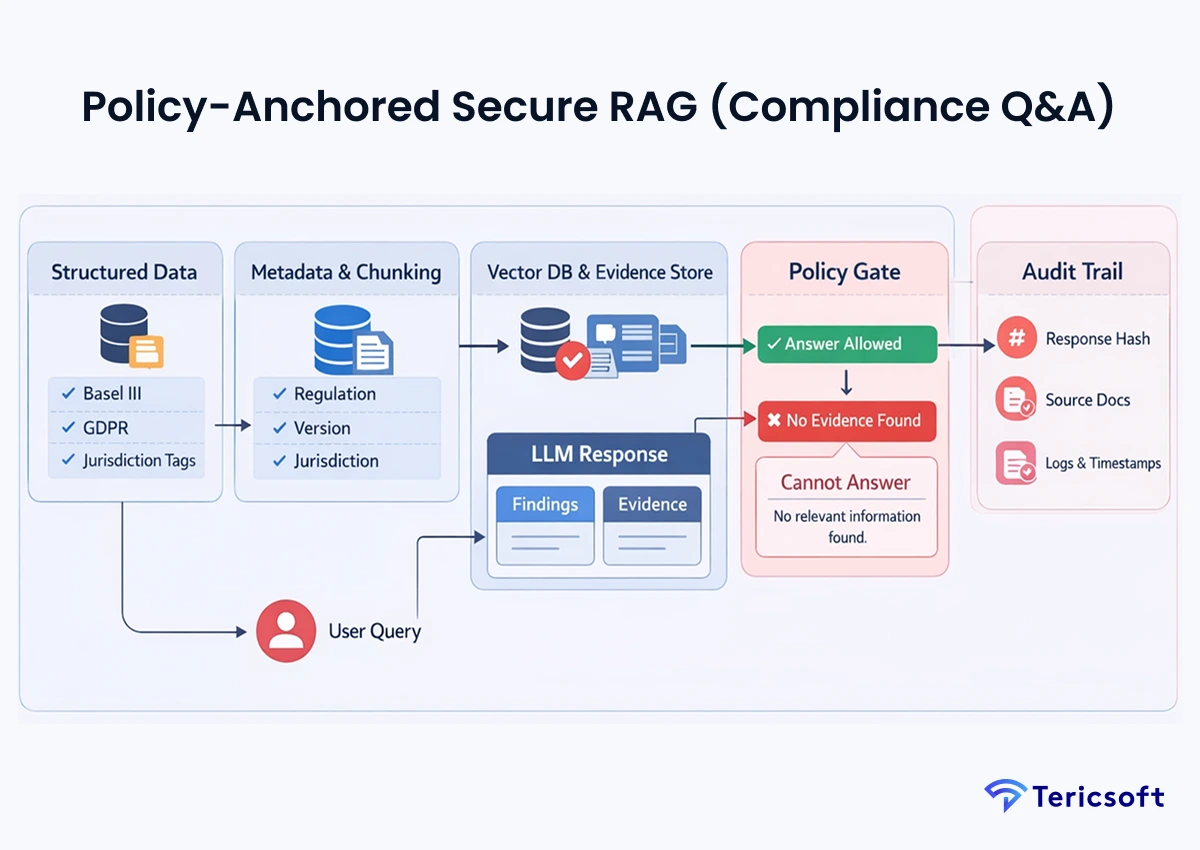
1: Policy-Anchored Secure RAG (Compliance Q&A)
The Mechanism: This system utilizes a strict hierarchy and immutable logic where the LLM provided with a "negative constraint": "If the retrieved context does not contain the answer, you must state that you cannot find the information."
- Compliance-first retrieval pipelines: Data is indexed with metadata identifying the specific regulatory version and jurisdiction.
- Regulatory traceability: Every response generates a unique hash linked to source documents, ensuring no "creative writing" by the Al.
- Explainable Al outputs for audits: The output is structured to clearly separate "Findings" from "Evidence."
- Use Case: Internal compliance copilots to interpret complex Basel III or GDPR requirements.
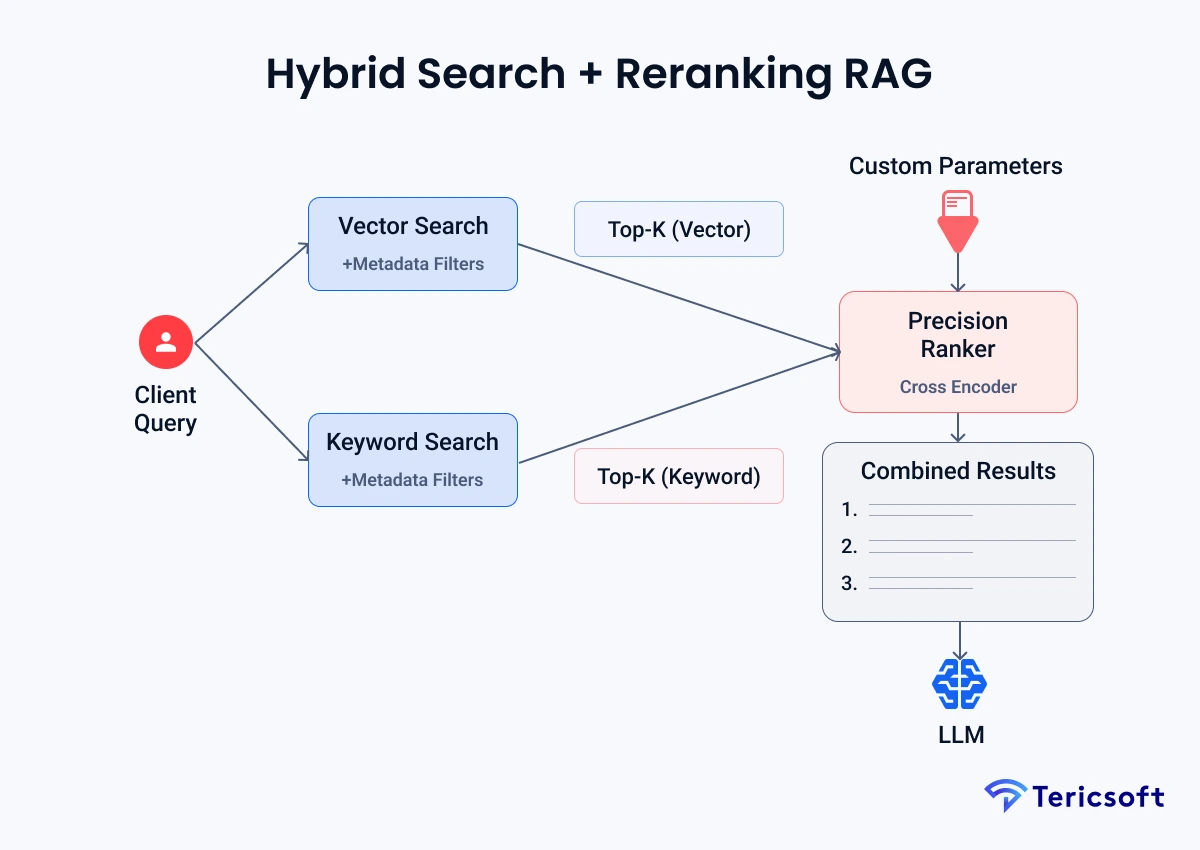
2: Hybrid Search + Reranking RAG (Operations Knowledge Engine)
The Mechanism: Financial terminology is alphanumeric and dense, such as SWIFT codes or ticker symbols. Pure semantic search often misses these. We combine Vector Search (meaning) with Keyword Search (exact codes).
- Vector + keyword + metadata retrieval: Captures both the "intent" of a query and the specific alphanumeric "code" referenced.
- Rerankers for precision: A cross-encoder re-evaluates the top 20 results to ensure the most relevant chunk is prioritized.
- Low hallucination risk: Precision-focused reranking prevents the LLM from trying to connect unrelated data points.
- Use Case: Ops knowledge portals where accuracy on specific transaction codes is a requirement for operational survival.
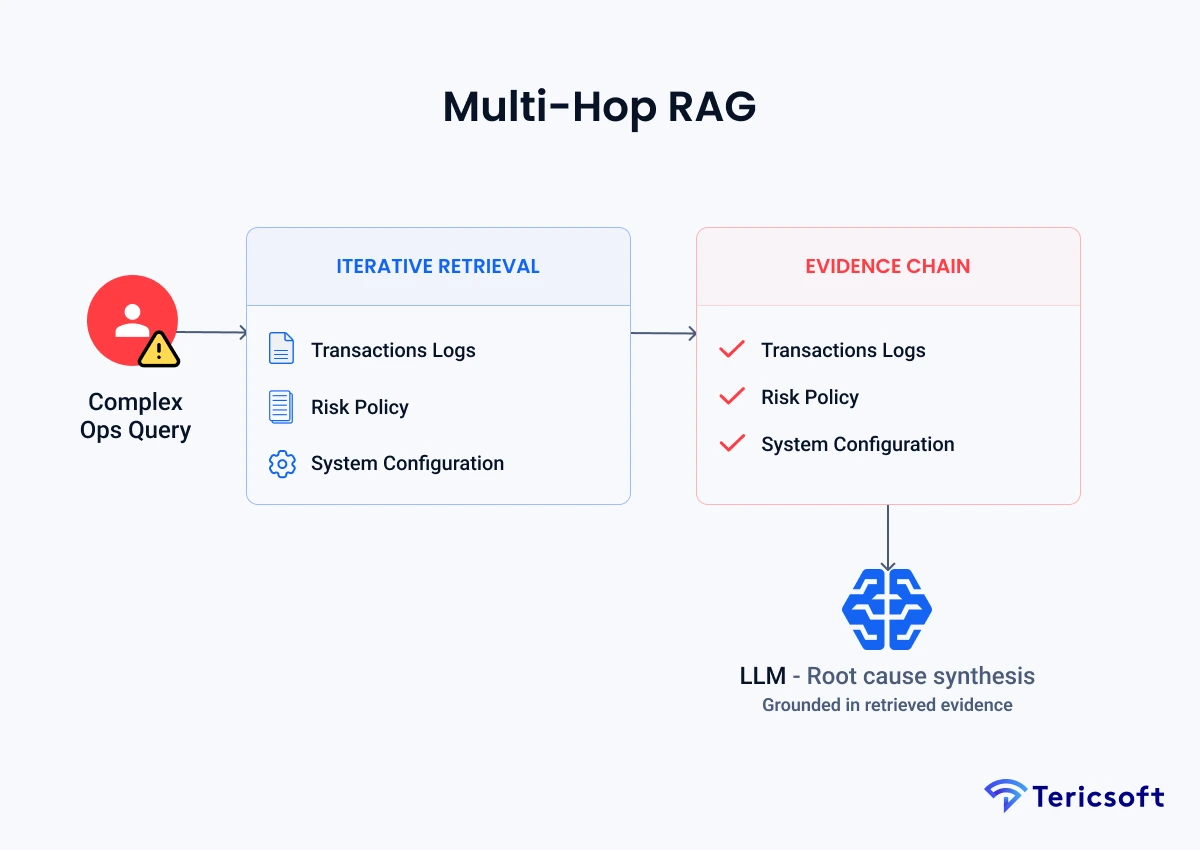
3: Multi-Hop RAG (Root-Cause Investigation Assistant)
The Mechanism: Complex financial questions rarely exist in a single document. Multi-hop RAG performs iterative reasoning, retrieving document A (the log), using that to realize it needs document B (the policy), and synthesizing the chain.
- Multi-document reasoning: Connects transaction logs with risk policies across disconnected silos.
- Stepwise evidence chaining: The Al documents its "thinking process" between hops for human verification.
- Incident analysis workflows: Reconstructs the timeline of an operational failure across multiple systems.
- Use Case: Forensic investigations into payment failures or complex transaction anomalies.
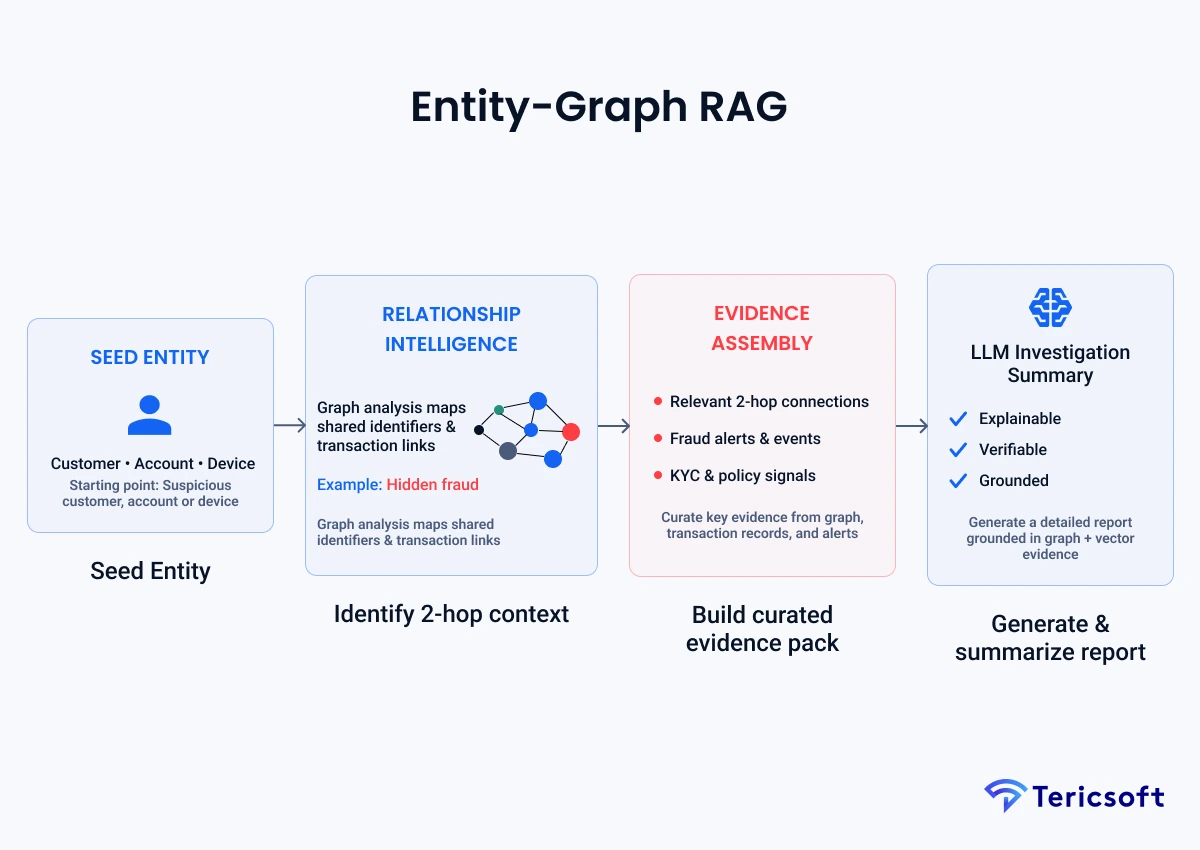
4: Entity-Graph RAG (AML & Fraud Network Reasoning)
The Mechanism: Fraud is a network problem, not a text problem. This architecture integrates a Knowledge Graph (such as Neo4j) with the vector database.
- Graph-based retrieval: Extracts relationships between accounts, IPs, and entities that are "2-hops" away.
- Entity relationships: Understands that "Customer A" is linked to "Company B" through a shared address, not just a keyword.
- Pattern discovery: Flags suspicious clusters that appear disconnected in standard text databases.
- Use Case: AML investigations and identifying sophisticated fraud rings for risk management.
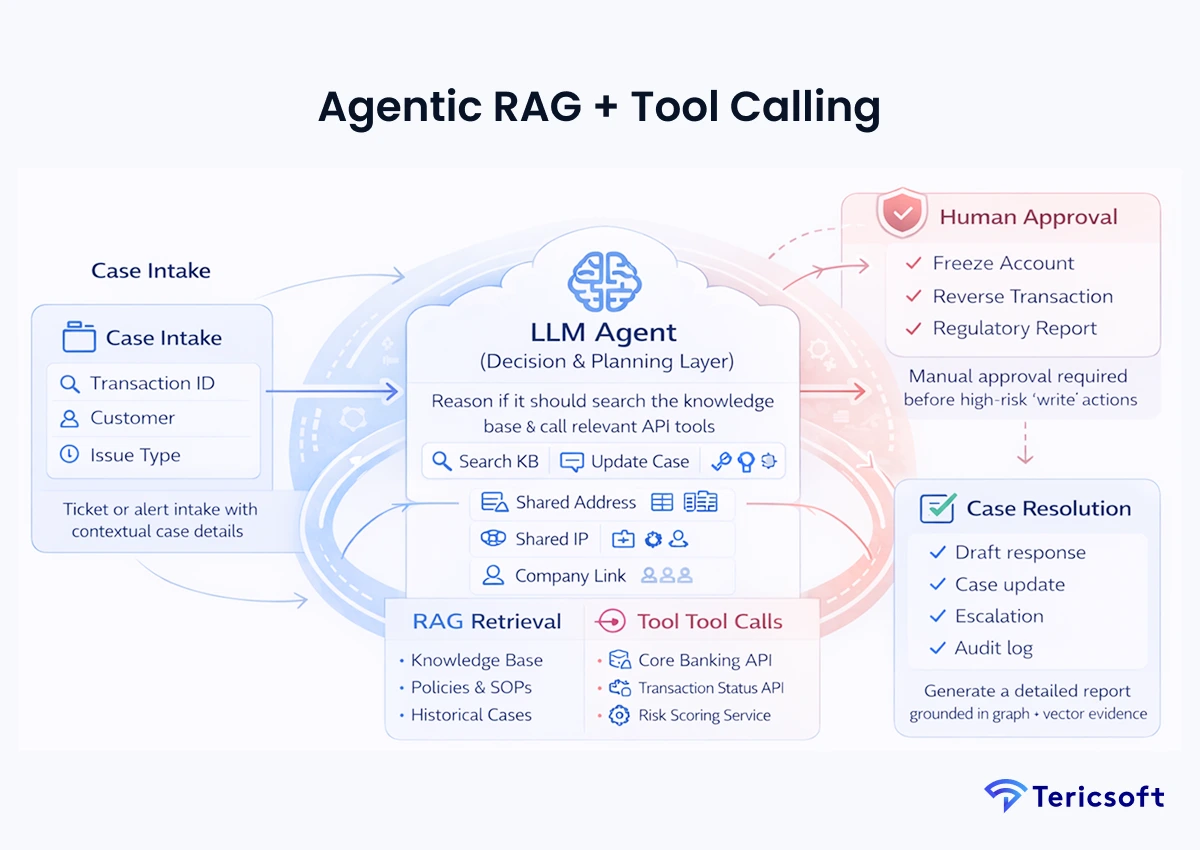
5: Agentic RAG + Tool Calling (Case Management Copilot)
The Mechanism: Moving from "knowing" to "doing." The LLM acts as an "agent" that determines if it needs to search the knowledge base or execute a specific API tool.
- Autonomous task execution: The agent can draft a response and then call an API to flag a transaction for review.
- Tool orchestration: Manages multiple API calls to gather real-time data from legacy core banking systems.
- Human-in-the-loop controls: Requires manual approval before executing high-risk "write" actions like account freezes.
- Use Case: Scaling back-office efficiency by automating case resolution and escalation workflows.
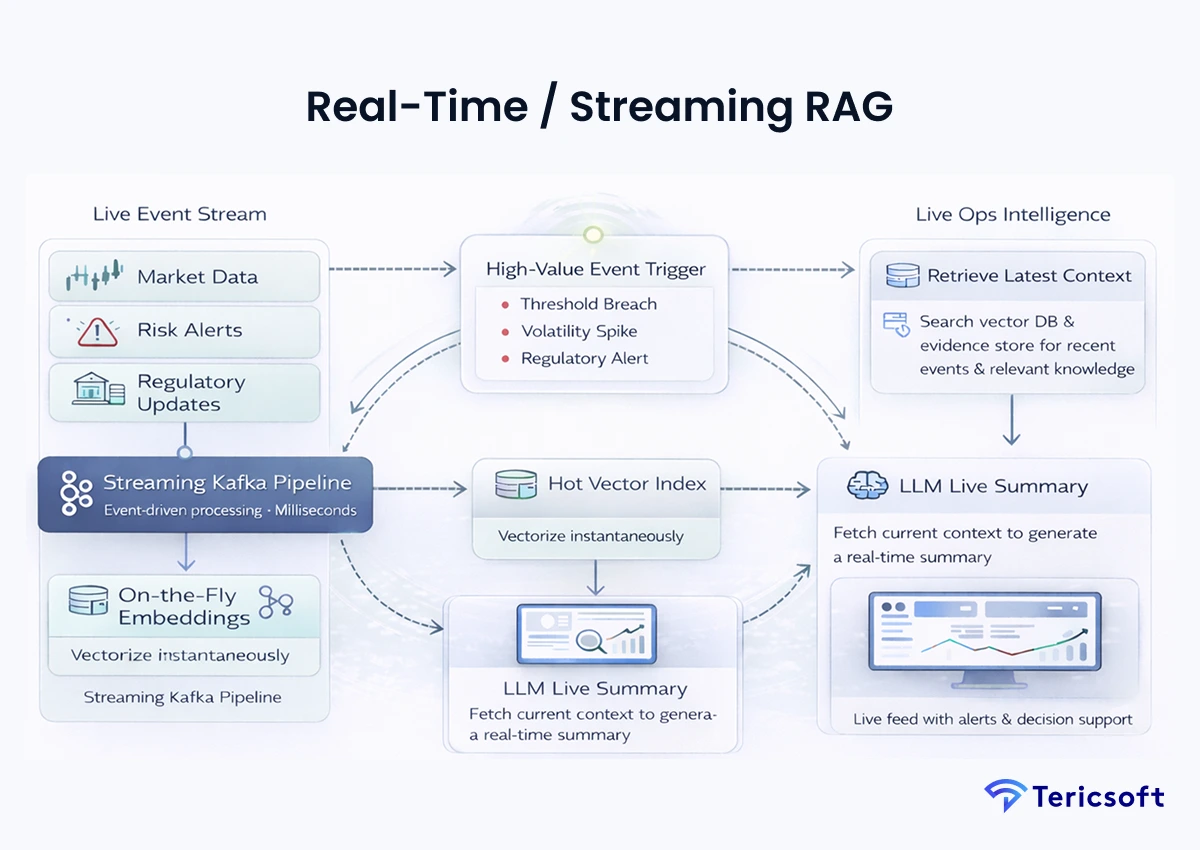
6: Real-Time / Streaming RAG (Live Operations Intelligence)
The Mechanism: In finance, data from-ten minutes ago is "historical " This uses event-driven pipelines (Kafka) to perform "on-the-fly" indexing.
- Streaming ingestion: New regulatory updates or market alerts are vectorized and searchable in milliseconds.
- Event-driven retrieval: Triggers an Al summary as soon as a high-value alert is generated by the system.
- Low-latency inference: Optimized for "right-now" operational awareness and liquidity monitoring.
- Use Case: "What's happening right now?" dashboards for market risk managers during volatility events.
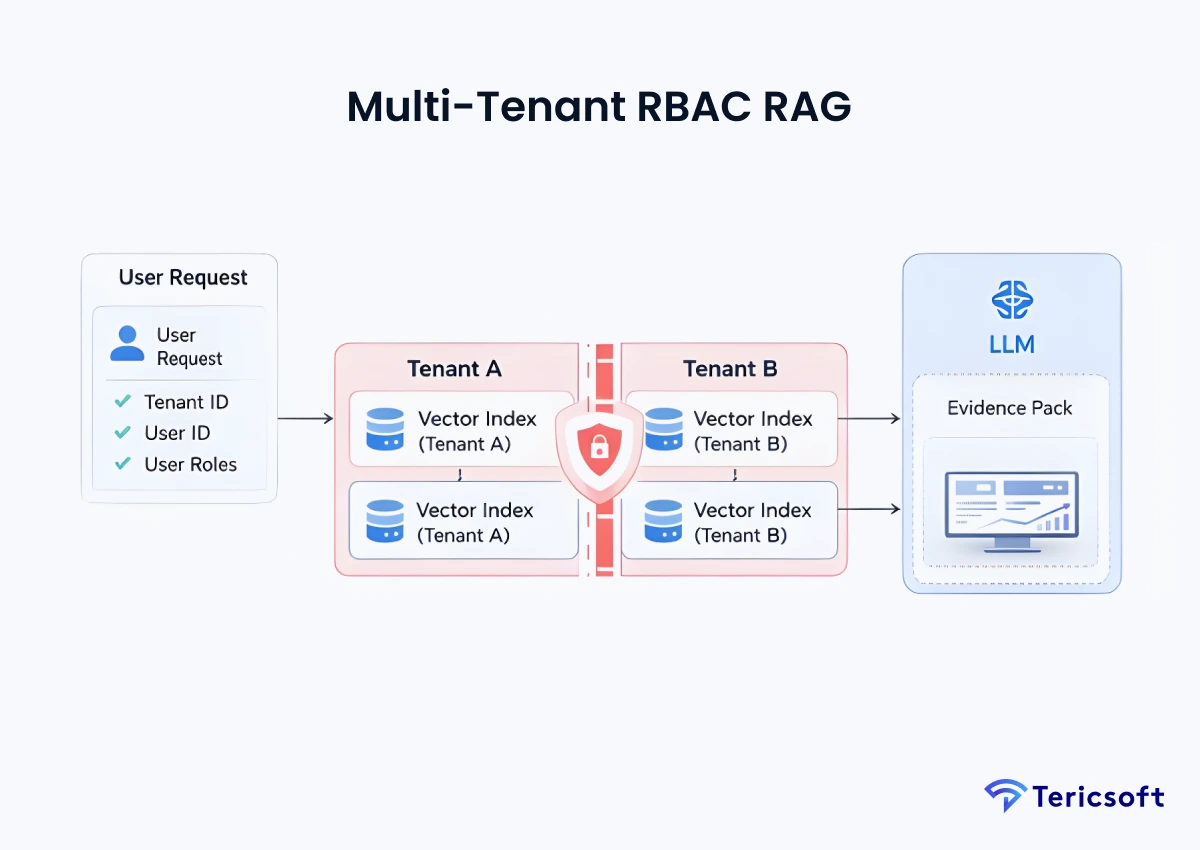
7: Multi-Tenant RBAC RAG (FinTech Platform Architecture)
The Mechanism: For SaaS platforms, data leakage between clients is a catastrophic failure. Permission logic is baked into the metadata filtering at the database level.
- Tenant isolation: Data is physically or logically partitioned by tenant_id to ensure no cross-contamination.
- Role-based retrieval: Filters the search space based on the specific user's access rights before the LLM sees it.
- Data boundary enforcement: Prevents an LLM from accidentally "learning" patterns across different clients.
- Use Case: SaaS FinTech platforms serving multiple enterprise clients with a single Al infrastructure.
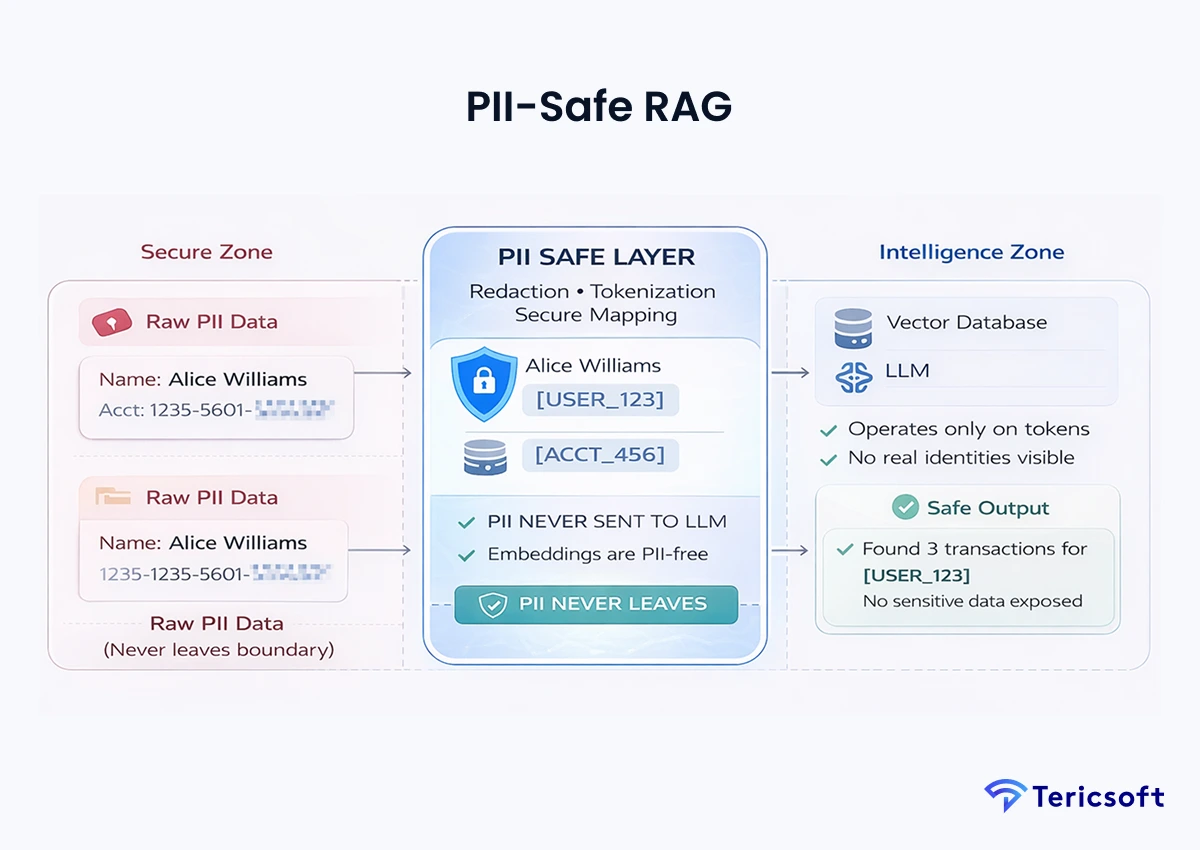
8: PII-Safe RAG (Redaction + Tokenization + Safe Output Layer)
The Mechanism: Sending PII to a public LLM API is a regulatory violation. This architecture redacts sensitive data before it ever leaves your secure environment.
- PIl masking: Replaces names and account numbers with tokens (such as [USER_123]) using local NER models.
- Secure embeddings: Ensures that the vectors themselves do not leak sensitive latent information.
- Output filters: Scans the Al's response to ensure no sensitive data was "guessed" or reconstructed.
- Use Case: Customer-facing Al systems and external-facing support portals that satisfy strict privacy mandates.
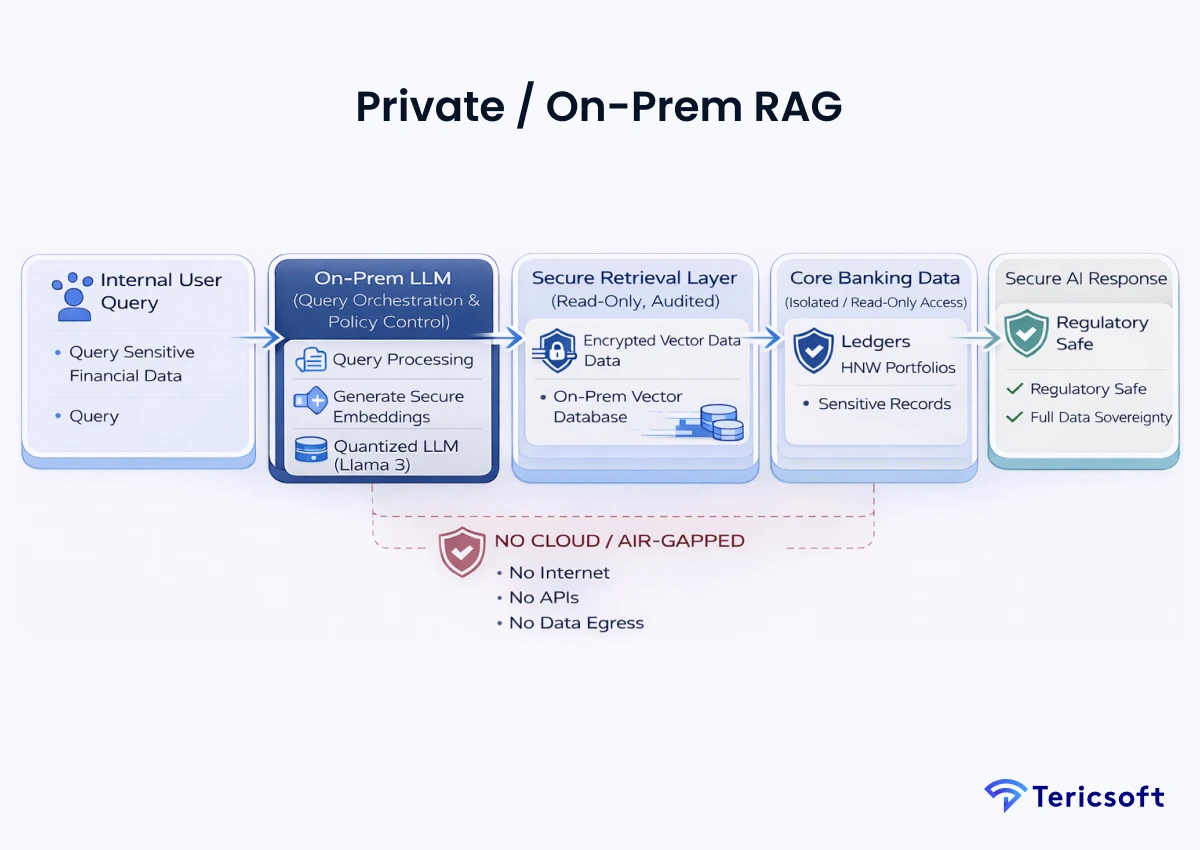
9: Private / On-Prem RAG (High-Risk Financial Data)
The Mechanism: For core banking, data sovereignty is non-negotiable. This runs entirely on private, air-gapped infrastructure.
- Private inference: Uses open-weights models (like Llama 3) optimized via quantization to run on local GPU clusters.
- Data sovereignty: Ensures that no data, not even encrypted, ever touches a third- party cloud provider.
- Regulatory-grade security: Built to meet the absolute highest standards of core banking compliance.
- Use Case: Core banking, sensitive datasets, and HNW portfolio management where cloud is not an option.
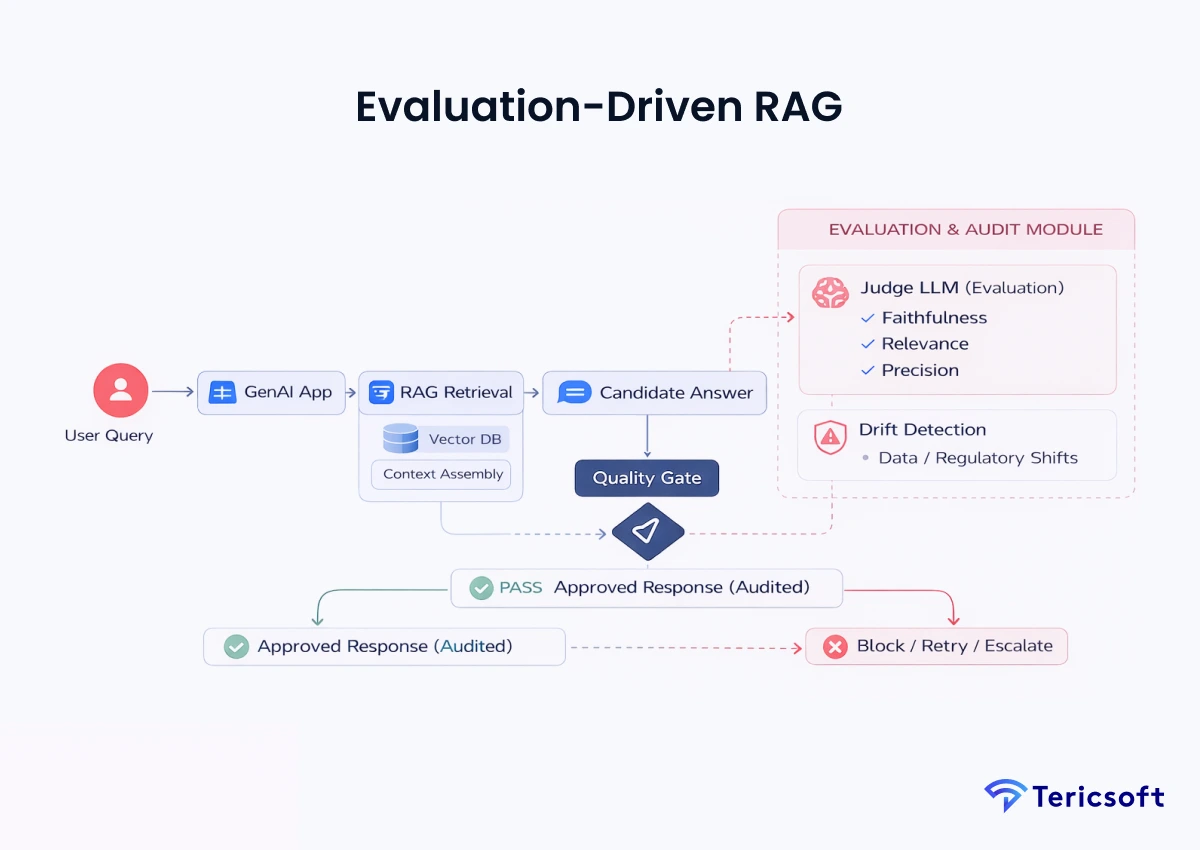
10: Evaluation-Driven RAG (Production-Quality Architecture)
The Mechanism: A production system requires constant auditing. This architecture uses a "judge-based" system where a secondary, specialized LLM audits the primary one.
- Continuous evaluation: Measures Faithfulness (hallucination check), Relevance, and Precision for every interaction.
- Drift detection: Flags when the Al's performance degrades due to new regulatory patterns or data shifts.
- Quality gates: Automatically prevents non-compliant or inaccurate responses from reaching the end-user.
- Use Case: Enterprise-scale Al systems requiring long-term reliability and auditable performance for institutional oversight.
How to Secure LLM + RAG in FinTech
Architecture is nothing without defense. In a sector where security is synonymous with data integrity, we implement a "defense-in-depth" strategy that ensures every data point and model interaction remains within the institution's risk appetite:
Identity-aware retrieval
Retrieval must be an extension of your existing IAM (Identity and Access Management) strategy. If a user can't see the document in your legacy system, the Al shouldn't see it for them.
Prompt injection defense
FinTechs must implement "firewalls" that detect adversarial prompts designed to leak system instructions or bypass safety filters.
Output validation
Hard-coded guardrails must scan every Al response for prohibited financial advice, toxicity, or unmasked PIl before it is rendered to the user.
Regulatory compliance (PCI-DSS, SOC2, ISO, GDPR)
Every component of the RAG pipeline, from the vector database to the inference engine, must be mapped to specific regulatory controls.
Cost & Latency Optimization for RAG in Operations
Building an accurate system is useless if it is too expensive to scale or too slow for real- time operations. Optimization in FinTech RAG is about finding the "sweet spot" where precision meets performance:
Intelligent chunking strategies
By using semantic chunking instead of fixed-size chunks, we send only the most relevant text to the LLM, reducing token costs by up to 40%.
Cache-aware architectures
Implementing semantic caching allows the system to reuse previous high-quality answers for similar queries, reducing inference latency from seconds to milliseconds.
Tiered model routing
Simple queries are routed to smaller models (such as GPT-40-mini), while complex reasoning is reserved for "frontier" models, balancing cost and performance.
ROI-driven architecture decisions
Focusing on "operational efficiency" ensures that every architectural dollar translates to a measurable reduction in risk and manual labor.
Common Architectural Mistakes FinTech Teams Make
Even the most experienced teams can fall into architectural traps that derail production timelines. These are not just technical errors; they are risks to the firm's balance sheet and reputation:
- Over-indexing on model choice: Thinking a better model fixes a bad data layer.
- Ignoring evaluation pipelines: Shipping without a way to prove to regulators or the board that the Al is actually accurate.
- Treating compliance as an afterthought: Designing a "demo" that can never meet bank-grade security standards.
- Shipping MVP architectures into production: Using simple, unoptimized frameworks for high-stakes financial data.
How We Architect LLM + RAG Systems for FinTech Enterprises
At Tericsoft, we understand that architecture is the product. We don't just build models; we build the infrastructure of trust. Our methodology is designed to bridge the gap between Al hype and institutional reality, focusing on the following four pillars:
- Compliance-first design philosophy: Security is the first line of code, not the last.
- Secure-by-default architectures: PIl-safe and permission-aware pipelines built for the enterprise.
- Production-ready evaluation frameworks: Quantitative proof that your Al is accurate and regulator-ready.
- Long-term scalability planning: Systems that grow with your transaction volume without breaking.
LLM + RAG architecture in FinTech combines large language models with real-time, permissioned data retrieval to deliver accurate, compliant, and auditable AI responses.
RAG is mandatory because FinTech requires traceability, real-time data grounding, and audit-ready outputs—capabilities standalone LLMs cannot guarantee.
They reduce hallucinations by grounding every AI response in verified internal data, policies, and regulatory documents instead of probabilistic model knowledge.
Yes, when designed correctly, LLM + RAG architectures support PCI-DSS, SOC 2, ISO, and GDPR by enforcing data access controls, lineage, and explainability.
Common use cases include compliance Q&A, fraud investigation, AML analysis, risk assessment, operations knowledge management, and audit automation.


