






What is Data Privacy in LLM, how does it secure sensitive enterprise intelligence at scale, and why is it becoming essential for organizations seeking to deploy trusted Al agents without risking customer data or regulatory credibility?
The morning rush at a major bank branch is an archetype of systemic friction. Long queues, mismatched counters, and the rhythmic rustle of repeated paperwork create a bottleneck that slows the pulse of global commerce. To reclaim efficiency and operational agility, financial institutions are aggressively digitizing these legacy workflows. They are deploying Al powered chatbots and autonomous agents that promise a landscape of persistent support and instantaneous resolution. Yet, beneath this glittering promise of velocity lies a profound, systemic tension. Artificial Intelligence necessitates data to manifest intelligence. In the banking sector, that data: ranging from credit card details and transaction histories to sensitive KYC documents: constitutes the most private information an individual can possess.
The pilot worked perfectly. Perhaps, it worked too well. In a recent deployment for a mid sized FinTech firm, a successful dispute resolution agent handled a complex multi currency claim in seconds. It was a masterpiece of empathy and logic. But as the summary flickered on the screen, a sobering realization settled over the executive team. The Al had reached its conclusion by referencing a specific, highly confidential internal risk assessment that resided exclusively in the private archives of the leadership team.
The CTO did not perceive a productivity milestone on that screen. They perceived a mirror. The Al was reflecting the enterprise's most private internal consciousness back to the world. It had ingested the organization's collective mind, proving that when digital transformation meets sensitive data, the boundary of trust becomes the primary product. This is the quiet epiphany hitting C-suites today: Privacy in the era of Generative Al is not a checkbox on a compliance form. It is the fundamental architecture of trust. Banks are no longer merely moving capital. They are moving intelligence. That intelligence is fueled by the very data that regulators and customers expect to remain sequestered in a vault.
"We shouldn't ask our customers to make a tradeoff between privacy and security. We need to offer them the best of both. Ultimately, protecting someone else's data protects all of us."
— Tim Cook, CEO of Apple
Insight: Frame privacy as part of Al risk governance, not just security. Mention that leading frameworks treat privacy risk as a core Al risk category across the lifecycle (design → deploy → monitor), which is why enterprises are building Al governance programs (policies, audits, accountability) before scaling agents.
By 2026, more than 80% of enterprises are expected to have used GenAl APls/models or deployed GenAl-enabled applications in production.
What Is Data Privacy in LLM? (Enterprise Reality, Not Theory)
In regulated sectors, protecting data is no longer as simple as "locking the door" with encryption. To understand why, we must look at how Large Language Models handle information differently than traditional systems.
The fundamental shift is moving from records to representations. Think of a traditional database as a filing cabinet: it holds specific documents in specific folders. If you shred a document, it is gone forever. An LLM, however, acts more like a student. It doesn't just store your data; it learns from it, turning information into complex mathematical patterns within its neural "brain."
This creates a unique challenge: a database forgets when you tell it to, but an LLM retains a mathematical memory of what it has seen. Sensitive information doesn't just sit in a file; it becomes part of the model's way of thinking. In the enterprise, customer data represents years of built-up trust. We cannot treat it as mere fuel for an Al engine; we must protect the integrity of that trust within this new, complex architecture.
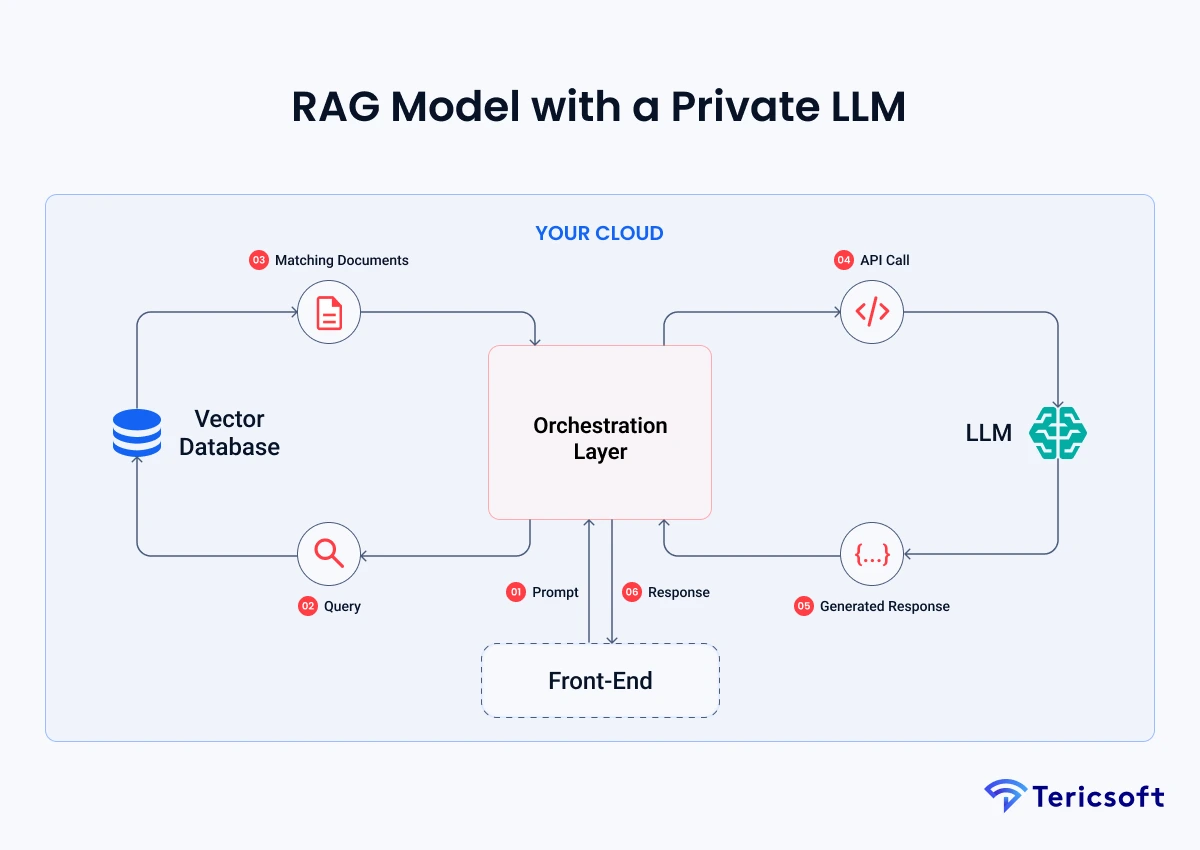
What Actually Happens When an LLM "Sees" Data
When we posit that an LLM "sees" data, we are leveraging a metaphor for a complex mathematical transfiguration. To secure Al at scale, leaders must transcend the notion of the model as a "reader" and instead view it as a "transformer." This transfiguration occurs in three distinct, high risk stages:
Stage 1: The Geometry of Language (The Embedding Layer) Your raw text undergoes Tokenization and Embedding. Every word or financial figure is converted into a coordinate in a high dimensional mathematical space. The model isn't reading history. It is mapping the semantic distance between that history and its global world knowledge. These vectors are high fidelity mathematical fingerprints. If a vector database is compromised, the original sensitive text can be reconstructed through inversion. This renders the "it's just numbers" defense a dangerous fallacy.
Stage 2: The Ephemeral Mirror (Inference-Time Contextualization) Data resides in the Context Window during the processing phase. While providers assert this memory is temporary, the data is physically maintained in the GPU's active memory. If the system lacks total architectural isolation, fragments of this context can persist in cache or be captured by Inference Telemetry. This telemetry is often logged by providers for optimization. This means your private prompt can become a permanent entry in a third party log that is theoretically accessible to their internal teams.
Insight: Explain that observability is where privacy often breaks in real enterprises: prompts, tool outputs, and retrieved passages end up in APM/logging systems, SIEMs, vendor consoles, or support tickets-creating unintentional retention.
Average organizations are now reporting 223 GenAl-related data policy violations per month.
Stage 3: The Persistent Shadow (Stochastic Memorization) The most misunderstood risk is Stochastic Memorization. When a model is fine tuned on private documents, it often absorbs specific facts into its underlying neural weights. Unlike a database, you cannot execute a delete command on a specific fact inside a neural network. That sensitive document becomes a permanent component of the model's logic. It is a shadow that can be coaxed out through clever adversarial probing by any actor with access to the model.
Organizations increasingly encounter an Al driven breach cost as data flows through unmanaged inference pipelines and decentralized model architectures. When enterprise data is siloed within Al systems or exposed via unvetted LLM tools, the financial consequences are amplified by the inability to track data lineage. This lack of centralized visibility creates a profound governance debt. It transforms every new Al pilot into a potential liability unless the underlying architecture is engineered for total data sovereignty.
Insight: State that training-data extraction has been demonstrated in peer-reviewed security research: attackers can recover verbatim or near-verbatim training examples via black-box querying, especially when models have memorized rare strings.
Why Open LLMs Create Anxiety for Regulated Industries
For regulated enterprises, the biggest hurdle to adopting Al is a constant sense of uncertainty. When you send sensitive information to a third-party cloud, you are essentially putting it into a "black box." It is difficult to see exactly how your data is handled, whether it is being saved for later, or if it is being used to train the model for everyone else.
Think of it this way: for decades, banks and hospitals have built high-security vaults to keep data safe. Using a public LLM is like taking a secret document out of that vault and handing it to a courier you don't fully control. Once that document (or prompt) leaves your hands, you can no longer prove it was destroyed or track who else might have seen it. In a world of strict rules and heavy audits, "trust us" is not a valid security plan. This is why many organizations feel that public models represent a crack in their carefully built fortresses.
The Human Side of Data Privacy
We must transcend the spreadsheet and acknowledge that loss of trust is significantly more detrimental than any technical system failure. When an employee copies a customer's financial history into a public Al tool out of convenience, they are not merely bypassing a corporate policy. They are eroding the brand's moral foundation.
47% of users access Al through personal apps (shadow Al).
This behavior is a systemic vulnerability. A privacy breach in an Al system feels more personal than a conventional database leak. It feels like an invasion of an intimate exchange. Because LLMs are designed to manifest empathy and conversational fluidity, a leak of that data feels like a betrayal of confidence. If a patient's diagnosis or a client's financial history becomes a training signal for a competitor's model, the damage is irreversible. We are stewards of something sacred when we manage customer interactions. In the enterprise, privacy is the active preservation of customer dignity.
From Open Al to Enterprise Al: Why Private LLMs Exist
The limitations of public models have catalyzed a fundamental paradigm shift: the rise of the Private LLM. Enterprises are reclaiming their digital sovereignty by transitioning away from "Al as a Service" and toward "Al as Infrastructure." In this new model, data ownership, inference boundaries, and the entire deployment environment are repatriated under the organization's absolute control.
This is a strategic trade. Enterprises are now electing to prioritize the absolute certainty of trust over the marginally higher general intelligence of public giants. A Private LLM ensures that your intellectual property and customer data never transcend your secure perimeter. This allows a bank or a hospital to define exactly what the model perceives, what it retains, and precisely where its logs reside. It is the evolution from being a consumer of Al to being an owner of Al. Hosting your own model weights and managing your own inference stack transforms Al from a potential liability into a sovereign strategic asset.
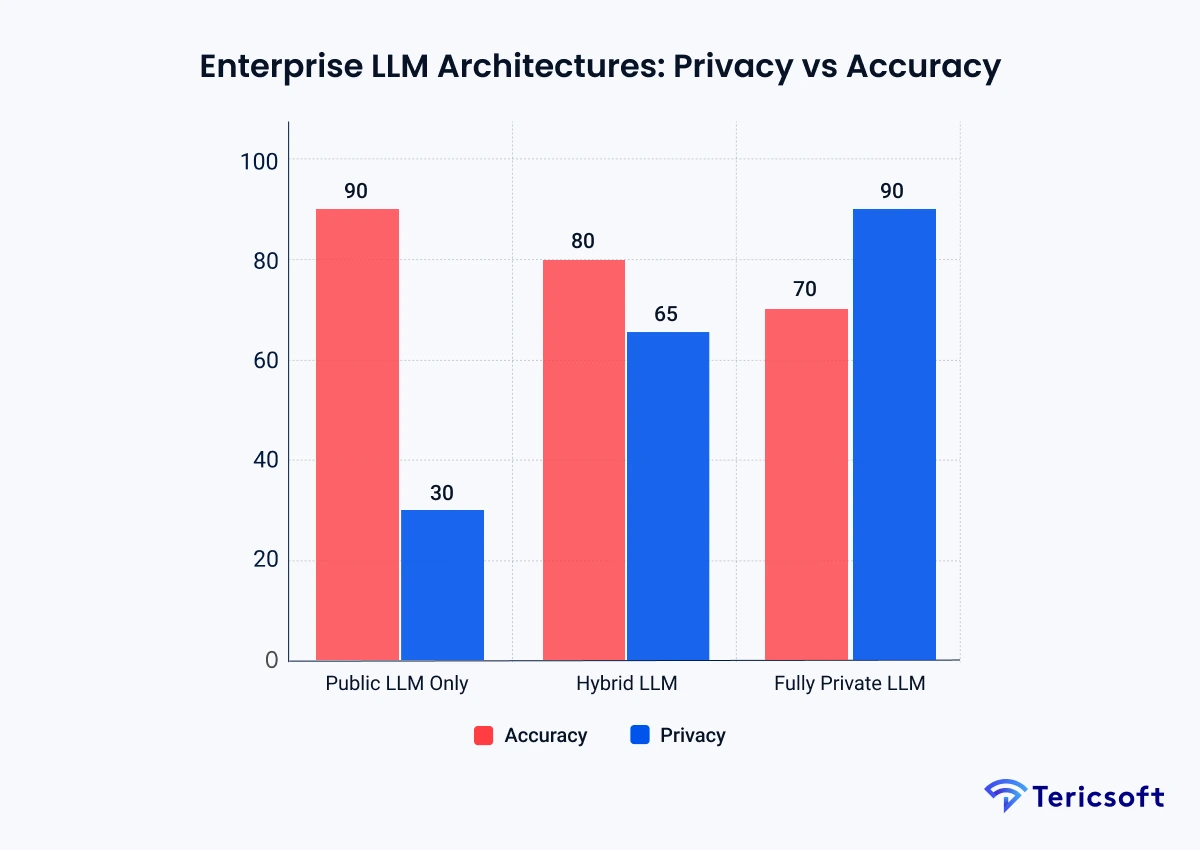
Enterprise LLM Architectures: Privacy, Accuracy, Exposure Spectrum
No single architecture is universally superior. It is always contextually appropriate. Serious enterprises evaluate their Al strategy across a spectrum of trade offs where performance and protection are in persistent negotiation.
Deep Dive: Why these percentages fluctuate
The fluctuation between these metrics is driven by three fundamental technical pillars:
- Parameter Scale vs. Reasoning (The Accuracy Basis): Accuracy in public models (90%) is a direct correlate of hyper scale compute. These models are trained on trillions of tokens with hundreds of billions of parameters, allowing them to capture complex nuances that smaller, private models might miss. When you migrate to a Private LLM (70%), you are often deploying models designed for local hardware constraints. While they excel at specialized tasks, they lose the "broad spectrum reasoning" of public giants, resulting in a decrement in general accuracy.
- Data Locality vs. Transit Risk (The Privacy Basis): Privacy scores fluctuate based on the physical and digital location of the inference. In a public model (30%), privacy is diminished because the data undergoes Transit Risk. It exits your firewall and enters a shared environment where logs and telemetry are beyond your purview. In a Private LLM (90%), the data remains Sovereign. It never exits your VPC or on premise hardware, effectively neutralizing the risk of third party exposure or accidental model training on your data.
- Log Ownership vs. Telemetry (The Exposure Basis): Data exposure is not merely about the model, but the footprint left behind. Public models have high exposure because the provider controls the telemetry. In a private setup, you maintain absolute custody of the logs. You can implement Zero Retention policies that you physically audit, ensuring that once an inference is complete, the data shadow is truly eradicated from the hardware cache.
Data Privacy in LLM Agents
When we move from simple chatbots to autonomous agents, the privacy risk intensifies exponentially. Agents perform multi step execution, maintain longitudinal memory, and execute autonomous actions. In a banking context, an agent might follow up on an email, initiate an internal ticket, and verify a transaction history across disparate systems. This requires:
- Scoped Memory: Longitudinal memories must be strictly governed to prevent context from one user leaking into another's session.
- Tool-Call Interception: Every request for data must be validated against the original user's specific permissions.
- Boundary Enforcement: Preventing agents from becoming super users with unintended access to sensitive data silos.
Without a privacy-first foundation, these agents become super-users with the ability to leak an entire organization's intelligence in a single tool call. The focus must shift from what an agent can do to what it is allowed to see.
Vector Database Privacy: The Silent Risk Layer
Embeddings can still manifest meaning through inversion attacks. Because vectors represent the semantic core of your data, they require vault level security. To secure these at scale, enterprises implement:
- Tenant Isolation: Cryptographic separation ensuring User A's vectors are never visible to User B.
- RBAC at the Vector Level: Ensuring Al only retrieves segments of data that the specific user is already authorized to access.
- Metadata Scrubbing: Eradicating sensitive identifiers from the metadata attached to vectors to prevent accidental exposure.
Learning Without Remembering Too Much (Improvement without Invasion)
The objective is to refine intelligence without being intrusive. Disciplined learning involves techniques like Synthetic Data Fine-Tuning, which trains on Al generated data that mimics patterns without containing specifics, and Differential Privacy, which introduces mathematical noise so the model learns the patterns of the forest without perceiving the individual trees. Improvement must occur at the aggregate level. It must never occur at the individual customer level. The goal is not to render the model blind, but to ensure it never becomes intrusive.
LLM Security Best Practices for Regulated Enterprises
Securing Al at scale requires a return to first principles:
- Private Deployment: Leveraging VPC or on premise environments for absolute control over the stack.
- Least-Privilege Access: Implementing robust RBAC for both the model and the vector store.
- Redaction Gateways: Neutralizing PII and sensitive identifiers before they reach the inference engine.
- Immutable Lineage: Maintaining a comprehensive audit trail of every retrieval and tool call.
- Human in the Loop: Requiring manual verification for high risk actions like fund transfers.
Prompt injection and insecure output handling are consistently ranked as top LLM application risks.
Al-powered security can significantly mitigate risk, but only if the Al itself is secured against internal leakage and unmanaged telemetry.
Why Privacy-First Al Becomes a Growth Lever
Responsible Al is not merely about mitigating fines. It is a competitive advantage that directly impacts the bottom line. When employees recognize that the system is private, they adopt it faster. They utilize it for high value, sensitive tasks that drive tangible ROI.
Furthermore, Customer Trust is a primary differentiator. Organizations that can demonstrate their Al is private will own the high trust markets of the future. Trust is no longer a soft metric; it is a prerequisite for scaling intelligence across the enterprise.
The Future Will Reward Responsible Intelligence
The future belongs to the Trusted Agent. Private LLMs will become the default for sophisticated enterprises. Governed agents will become the standard. Trust will become the ultimate KPI for Al success. The most advanced Al system in the world is worthless if stakeholders are apprehensive about its use. Responsible intelligence is the only intelligence that scales. We are transitioning toward a world of distributed intelligence, where every organization operates its own secure, private models that collaborate without leaking.
How Tericsoft Helps: Building Your Private Al Fortress
At Tericsoft, we don't just implement Al. We architect it for trust. We bridge the gap between innovation and security by transforming privacy from a defensive hurdle into a growth catalyst. We facilitate the transition from experimental risk to operational excellence through three specialized pillars:
- Private LLM Deployments: We host state of the art models within your secure infrastructure, whether it is a private cloud VPC or an on-premise air-gapped environment. This ensures total data locality and eliminates the transit risk associated with third party APls. By hosting your own weights, you gain full auditability and the capability to define zero retention policies that you physically control.
- Secure RAG Pipelines: We design vector database architectures with strict tenant isolation and robust RBAC. Our pipelines ensure that the Al only retrieves information the specific user is authorized to access in the source system. We implement metadata scrubbing and vector encryption to ensure that even if the storage layer is probed, the semantic core remains protected.
- Agent Governance Frameworks: We enable the deployment of autonomous agents without sacrificing control. Our frameworks implement tool call interception, PII redaction gateways, and Human in the Loop triggers. We provide the guardrail architecture that ensures your agents act with agency but never with unintended authority, making compliance a default state rather than an afterthought.
Data privacy in LLMs refers to protecting sensitive enterprise data as it flows through prompts, inference, training, and AI agent workflows.
Unlike databases, LLMs transform data into learned representations, making deletion, isolation, and governance significantly more challenging.
Private LLMs keep model weights, inference, logs, and data within enterprise-controlled environments, reducing third-party exposure and compliance risk.
Yes. AI agents access multiple systems, retain context, and act autonomously, which amplifies privacy risk without strict governance and access controls.
Yes. With privacy-first architectures, secure RAG pipelines, and governed AI agents, enterprises can deploy LLMs safely at scale.


